
commit
d1ce7b933f
100 changed files with 17144 additions and 0 deletions
+ 4691
- 0
.ipynb_checkpoints/eval-checkpoint.ipynb
File diff suppressed because it is too large
View File
+ 1799
- 0
.ipynb_checkpoints/train-checkpoint.ipynb
File diff suppressed because it is too large
View File
+ 176
- 0
README.md
View File
| # CSI: Novelty Detection via Contrastive Learning on Distributionally Shifted Instances | |||||
| Official PyTorch implementation of | |||||
| ["**CSI: Novelty Detection via Contrastive Learning on Distributionally Shifted Instances**"]( | |||||
| https://arxiv.org/abs/2007.08176) (NeurIPS 2020) by | |||||
| [Jihoon Tack*](https://jihoontack.github.io), | |||||
| [Sangwoo Mo*](https://sites.google.com/view/sangwoomo), | |||||
| [Jongheon Jeong](https://sites.google.com/view/jongheonj), | |||||
| and [Jinwoo Shin](http://alinlab.kaist.ac.kr/shin.html). | |||||
| <p align="center"> | |||||
| <img src=figures/shifting_transformations.png width="900"> | |||||
| </p> | |||||
| ## 1. Requirements | |||||
| ### Environments | |||||
| Currently, requires following packages | |||||
| - python 3.6+ | |||||
| - torch 1.4+ | |||||
| - torchvision 0.5+ | |||||
| - CUDA 10.1+ | |||||
| - scikit-learn 0.22+ | |||||
| - tensorboard 2.0+ | |||||
| - [torchlars](https://github.com/kakaobrain/torchlars) == 0.1.2 | |||||
| - [pytorch-gradual-warmup-lr](https://github.com/ildoonet/pytorch-gradual-warmup-lr) packages | |||||
| - [apex](https://github.com/NVIDIA/apex) == 0.1 | |||||
| - [diffdist](https://github.com/ag14774/diffdist) == 0.1 | |||||
| ### Datasets | |||||
| For CIFAR, please download the following datasets to `~/data`. | |||||
| * [LSUN_resize](https://www.dropbox.com/s/moqh2wh8696c3yl/LSUN_resize.tar.gz), | |||||
| [ImageNet_resize](https://www.dropbox.com/s/kp3my3412u5k9rl/Imagenet_resize.tar.gz) | |||||
| * [LSUN_fix](https://drive.google.com/file/d/1KVWj9xpHfVwGcErH5huVujk9snhEGOxE/view?usp=sharing), | |||||
| [ImageNet_fix](https://drive.google.com/file/d/1sO_-noq10mmziB1ECDyNhD5T4u5otyKA/view?usp=sharing) | |||||
| For ImageNet-30, please download the following datasets to `~/data`. | |||||
| * [ImageNet-30-train](https://drive.google.com/file/d/1B5c39Fc3haOPzlehzmpTLz6xLtGyKEy4/view), | |||||
| [ImageNet-30-test](https://drive.google.com/file/d/13xzVuQMEhSnBRZr-YaaO08coLU2dxAUq/view) | |||||
| * [CUB-200](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html), | |||||
| [Stanford Dogs](http://vision.stanford.edu/aditya86/ImageNetDogs/), | |||||
| [Oxford Pets](https://www.robots.ox.ac.uk/~vgg/data/pets/), | |||||
| [Oxford flowers](https://www.robots.ox.ac.uk/~vgg/data/flowers/), | |||||
| [Food-101](https://www.kaggle.com/dansbecker/food-101), | |||||
| [Places-365](http://data.csail.mit.edu/places/places365/val_256.tar), | |||||
| [Caltech-256](https://www.kaggle.com/jessicali9530/caltech256), | |||||
| [DTD](https://www.robots.ox.ac.uk/~vgg/data/dtd/) | |||||
| For Food-101, remove hotdog class to avoid overlap. | |||||
| ## 2. Training | |||||
| Currently, all code examples are assuming distributed launch with 4 multi GPUs. | |||||
| To run the code with single GPU, remove `-m torch.distributed.launch --nproc_per_node=4`. | |||||
| ### Unlabeled one-class & multi-class | |||||
| To train unlabeled one-class & multi-class models in the paper, run this command: | |||||
| ```train | |||||
| CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py --dataset <DATASET> --model <NETWORK> --mode simclr_CSI --shift_trans_type rotation --batch_size 32 --one_class_idx <One-Class-Index> | |||||
| ``` | |||||
| > Option --one_class_idx denotes the in-distribution of one-class training. | |||||
| > For multi-class training, set --one_class_idx as None. | |||||
| > To run SimCLR simply change --mode to simclr. | |||||
| > Total batch size should be 512 = 4 (GPU) * 32 (--batch_size option) * 4 (cardinality of shifted transformation set). | |||||
| ### Labeled multi-class | |||||
| To train labeled multi-class model (confidence calibrated classifier) in the paper, run this command: | |||||
| ```train | |||||
| # Representation train | |||||
| CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py --dataset <DATASET> --model <NETWORK> --mode sup_simclr_CSI --shift_trans_type rotation --batch_size 32 --epoch 700 | |||||
| # Linear layer train | |||||
| python train.py --mode sup_CSI_linear --dataset <DATASET> --model <NETWORK> --batch_size 32 --epoch 100 --shift_trans_type rotation --load_path <MODEL_PATH> | |||||
| ``` | |||||
| > To run SupCLR simply change --mode to sup_simclr, sup_linear for representation training and linear layer training respectively. | |||||
| > Total batch size should be same as above. Currently only supports rotation for shifted transformation. | |||||
| ## 3. Evaluation | |||||
| We provide the checkpoint of the CSI pre-trained model. Download the checkpoint from the following link: | |||||
| - One-class CIFAR-10: [ResNet-18](https://drive.google.com/drive/folders/1z02i0G_lzrZe0NwpH-tnjpO8pYHV7mE9?usp=sharing) | |||||
| - Unlabeled (multi-class) CIFAR-10: [ResNet-18](https://drive.google.com/file/d/1yUq6Si6hWaMa1uYyLDHk0A4BrPIa8ECV/view?usp=sharing) | |||||
| - Unlabeled (multi-class) ImageNet-30: [ResNet-18](https://drive.google.com/file/d/1KucQWSik8RyoJgU-fz8XLmCWhvMOP7fT/view?usp=sharing) | |||||
| - Labeled (multi-class) CIFAR-10: [ResNet-18](https://drive.google.com/file/d/1rW2-0MJEzPHLb_PAW-LvCivHt-TkDpRO/view?usp=sharing) | |||||
| ### Unlabeled one-class & multi-class | |||||
| To evaluate my model on unlabeled one-class & multi-class out-of-distribution (OOD) detection setting, run this command: | |||||
| ```eval | |||||
| python eval.py --mode ood_pre --dataset <DATASET> --model <NETWORK> --ood_score CSI --shift_trans_type rotation --print_score --ood_samples 10 --resize_factor 0.54 --resize_fix --one_class_idx <One-Class-Index> --load_path <MODEL_PATH> | |||||
| ``` | |||||
| > Option --one_class_idx denotes the in-distribution of one-class evaluation. | |||||
| > For multi-class evaluation, set --one_class_idx as None. | |||||
| > The resize_factor & resize fix option fix the cropping size of RandomResizedCrop(). | |||||
| > For SimCLR evaluation, change --ood_score to simclr. | |||||
| ### Labeled multi-class | |||||
| To evaluate my model on labeled multi-class accuracy, ECE, OOD detection setting, run this command: | |||||
| ```eval | |||||
| # OOD AUROC | |||||
| python eval.py --mode ood --ood_score baseline_marginalized --print_score --dataset <DATASET> --model <NETWORK> --shift_trans_type rotation --load_path <MODEL_PATH> | |||||
| # Accuray & ECE | |||||
| python eval.py --mode test_marginalized_acc --dataset <DATASET> --model <NETWORK> --shift_trans_type rotation --load_path <MODEL_PATH> | |||||
| ``` | |||||
| > This option is for marginalized inference. | |||||
| > For single inference (also used for SupCLR) change --ood_score baseline in first command, | |||||
| > and --mode test_acc in second command. | |||||
| ## 4. Results | |||||
| Our model achieves the following performance on: | |||||
| ### One-Class Out-of-Distribution Detection | |||||
| | Method | Dataset | AUROC (Mean) | | |||||
| | --------------|------------------ | --------------| | |||||
| | SimCLR | CIFAR-10-OC | 87.9% | | |||||
| | Rot+Trans | CIFAR-10-OC | 90.0% | | |||||
| | CSI (ours) | CIFAR-10-OC | 94.3% | | |||||
| We only show CIFAR-10 one-class result in this repo. For other setting, please see our paper. | |||||
| ### Unlabeled Multi-Class Out-of-Distribution Detection | |||||
| | Method | Dataset | OOD Dataset | AUROC (Mean) | | |||||
| | --------------|------------------ |---------------|--------------| | |||||
| | Rot+Trans | CIFAR-10 | CIFAR-100 | 82.5% | | |||||
| | CSI (ours) | CIFAR-10 | CIFAR-100 | 89.3% | | |||||
| We only show CIFAR-10 to CIFAR-100 OOD detection result in this repo. For other OOD dataset results, see our paper. | |||||
| ### Labeled Multi-Class Result | |||||
| | Method | Dataset | OOD Dataset | Acc | ECE | AUROC (Mean) | | |||||
| | ---------------- |------------------ |---------------|-------|-------|--------------| | |||||
| | SupCLR | CIFAR-10 | CIFAR-100 | 93.9% | 5.54% | 88.3% | | |||||
| | CSI (ours) | CIFAR-10 | CIFAR-100 | 94.8% | 4.24% | 90.6% | | |||||
| | CSI-ensem (ours) | CIFAR-10 | CIFAR-100 | 96.0% | 3.64% | 92.3% | | |||||
| We only show CIFAR-10 with CIFAR-100 as OOD in this repo. For other dataset results, please see our paper. | |||||
| ## 5. New OOD dataset | |||||
| <p align="center"> | |||||
| <img src=figures/fixed_ood_benchmarks.png width="600"> | |||||
| </p> | |||||
| We find that current benchmark datasets for OOD detection, are visually far from in-distribution datasets (e.g. CIFAR). | |||||
| To address this issue, we provide new datasets for OOD detection evaluation: | |||||
| [LSUN_fix](https://drive.google.com/file/d/1KVWj9xpHfVwGcErH5huVujk9snhEGOxE/view?usp=sharing), | |||||
| [ImageNet_fix](https://drive.google.com/file/d/1sO_-noq10mmziB1ECDyNhD5T4u5otyKA/view?usp=sharing). | |||||
| See the above figure for the visualization of current benchmark and our dataset. | |||||
| To generate OOD datasets, run the following codes inside the `./datasets` folder: | |||||
| ```OOD dataset generation | |||||
| # ImageNet FIX generation code | |||||
| python imagenet_fix_preprocess.py | |||||
| # LSUN FIX generation code | |||||
| python lsun_fix_preprocess.py | |||||
| ``` | |||||
| ## Citation | |||||
| ``` | |||||
| @inproceedings{tack2020csi, | |||||
| title={CSI: Novelty Detection via Contrastive Learning on Distributionally Shifted Instances}, | |||||
| author={Jihoon Tack and Sangwoo Mo and Jongheon Jeong and Jinwoo Shin}, | |||||
| booktitle={Advances in Neural Information Processing Systems}, | |||||
| year={2020} | |||||
| } | |||||
| ``` |
+ 119
- 0
common/LARS.py
View File
| """ | |||||
| References: | |||||
| - https://github.com/PyTorchLightning/PyTorch-Lightning-Bolts/blob/master/pl_bolts/optimizers/lars_scheduling.py | |||||
| - https://github.com/NVIDIA/apex/blob/master/apex/parallel/LARC.py | |||||
| - https://arxiv.org/pdf/1708.03888.pdf | |||||
| - https://github.com/noahgolmant/pytorch-lars/blob/master/lars.py | |||||
| """ | |||||
| import torch | |||||
| from .wrapper import OptimWrapper | |||||
| # from torchlars._adaptive_lr import compute_adaptive_lr # Impossible to build extensions | |||||
| __all__ = ["LARS"] | |||||
| class LARS(OptimWrapper): | |||||
| """Implements 'LARS (Layer-wise Adaptive Rate Scaling)'__ as Optimizer a | |||||
| :class:`~torch.optim.Optimizer` wrapper. | |||||
| __ : https://arxiv.org/abs/1708.03888 | |||||
| Wraps an arbitrary optimizer like :class:`torch.optim.SGD` to use LARS. If | |||||
| you want to the same performance obtained with small-batch training when | |||||
| you use large-batch training, LARS will be helpful:: | |||||
| Args: | |||||
| optimizer (Optimizer): | |||||
| optimizer to wrap | |||||
| eps (float, optional): | |||||
| epsilon to help with numerical stability while calculating the | |||||
| adaptive learning rate | |||||
| trust_coef (float, optional): | |||||
| trust coefficient for calculating the adaptive learning rate | |||||
| Example:: | |||||
| base_optimizer = optim.SGD(model.parameters(), lr=0.1) | |||||
| optimizer = LARS(optimizer=base_optimizer) | |||||
| output = model(input) | |||||
| loss = loss_fn(output, target) | |||||
| loss.backward() | |||||
| optimizer.step() | |||||
| """ | |||||
| def __init__(self, optimizer, trust_coef=0.02, clip=True, eps=1e-8): | |||||
| if eps < 0.0: | |||||
| raise ValueError("invalid epsilon value: , %f" % eps) | |||||
| if trust_coef < 0.0: | |||||
| raise ValueError("invalid trust coefficient: %f" % trust_coef) | |||||
| self.optim = optimizer | |||||
| self.eps = eps | |||||
| self.trust_coef = trust_coef | |||||
| self.clip = clip | |||||
| def __getstate__(self): | |||||
| self.optim.__get | |||||
| lars_dict = {} | |||||
| lars_dict["trust_coef"] = self.trust_coef | |||||
| lars_dict["clip"] = self.clip | |||||
| lars_dict["eps"] = self.eps | |||||
| return (self.optim, lars_dict) | |||||
| def __setstate__(self, state): | |||||
| self.optim, lars_dict = state | |||||
| self.trust_coef = lars_dict["trust_coef"] | |||||
| self.clip = lars_dict["clip"] | |||||
| self.eps = lars_dict["eps"] | |||||
| @torch.no_grad() | |||||
| def step(self, closure=None): | |||||
| weight_decays = [] | |||||
| for group in self.optim.param_groups: | |||||
| weight_decay = group.get("weight_decay", 0) | |||||
| weight_decays.append(weight_decay) | |||||
| # reset weight decay | |||||
| group["weight_decay"] = 0 | |||||
| # update the parameters | |||||
| for p in group["params"]: | |||||
| if p.grad is not None: | |||||
| self.update_p(p, group, weight_decay) | |||||
| # update the optimizer | |||||
| self.optim.step(closure=closure) | |||||
| # return weight decay control to optimizer | |||||
| for group_idx, group in enumerate(self.optim.param_groups): | |||||
| group["weight_decay"] = weight_decays[group_idx] | |||||
| def update_p(self, p, group, weight_decay): | |||||
| # calculate new norms | |||||
| p_norm = torch.norm(p.data) | |||||
| g_norm = torch.norm(p.grad.data) | |||||
| if p_norm != 0 and g_norm != 0: | |||||
| # calculate new lr | |||||
| divisor = g_norm + p_norm * weight_decay + self.eps | |||||
| adaptive_lr = (self.trust_coef * p_norm) / divisor | |||||
| # clip lr | |||||
| if self.clip: | |||||
| adaptive_lr = min(adaptive_lr / group["lr"], 1) | |||||
| # update params with clipped lr | |||||
| p.grad.data += weight_decay * p.data | |||||
| p.grad.data *= adaptive_lr | |||||
| from torch.optim import SGD | |||||
| from pylot.util import delegates, separate_kwargs | |||||
| class SGDLARS(LARS): | |||||
| @delegates(to=LARS.__init__) | |||||
| @delegates(to=SGD.__init__, keep=True, but=["eps", "trust_coef"]) | |||||
| def __init__(self, params, **kwargs): | |||||
| sgd_kwargs, lars_kwargs = separate_kwargs(kwargs, SGD.__init__) | |||||
| optim = SGD(params, **sgd_kwargs) | |||||
| super().__init__(optim, **lars_kwargs) |
+ 0
- 0
common/__init__.py
View File
BIN
common/__init__.pyc
View File
BIN
common/__pycache__/LARS.cpython-37.pyc
View File
BIN
common/__pycache__/__init__.cpython-36.pyc
View File
BIN
common/__pycache__/__init__.cpython-37.pyc
View File
BIN
common/__pycache__/common.cpython-36.pyc
View File
BIN
common/__pycache__/common.cpython-37.pyc
View File
BIN
common/__pycache__/eval.cpython-36.pyc
View File
BIN
common/__pycache__/eval.cpython-37.pyc
View File
+ 0
- 0
common/__pycache__/eval.cpython-37.pyc.2498080381488
View File
+ 0
- 0
common/__pycache__/eval.cpython-37.pyc.2731703741232
View File
BIN
common/__pycache__/train.cpython-36.pyc
View File
BIN
common/__pycache__/train.cpython-37.pyc
View File
+ 114
- 0
common/common.py
View File
| from argparse import ArgumentParser | |||||
| def parse_args(default=False): | |||||
| """Command-line argument parser for training.""" | |||||
| parser = ArgumentParser(description='Pytorch implementation of CSI') | |||||
| parser.add_argument('--dataset', help='Dataset', | |||||
| choices=['cifar10', 'cifar100', 'imagenet', 'CNMC', 'CNMC_grayscale'], type=str) | |||||
| parser.add_argument('--one_class_idx', help='None: multi-class, Not None: one-class', | |||||
| default=None, type=int) | |||||
| parser.add_argument('--model', help='Model', | |||||
| choices=['resnet18', 'resnet18_imagenet'], type=str) | |||||
| parser.add_argument('--mode', help='Training mode', | |||||
| default='simclr', type=str) | |||||
| parser.add_argument('--simclr_dim', help='Dimension of simclr layer', | |||||
| default=128, type=int) | |||||
| parser.add_argument('--shift_trans_type', help='shifting transformation type', default='none', | |||||
| choices=['rotation', 'cutperm', 'blur', 'randpers', 'sharp', 'blur_randpers', | |||||
| 'blur_sharp', 'randpers_sharp', 'blur_randpers_sharp', 'noise', 'none'], type=str) | |||||
| parser.add_argument("--local_rank", type=int, | |||||
| default=0, help='Local rank for distributed learning') | |||||
| parser.add_argument('--resume_path', help='Path to the resume checkpoint', | |||||
| default=None, type=str) | |||||
| parser.add_argument('--load_path', help='Path to the loading checkpoint', | |||||
| default=None, type=str) | |||||
| parser.add_argument("--no_strict", help='Do not strictly load state_dicts', | |||||
| action='store_true') | |||||
| parser.add_argument('--suffix', help='Suffix for the log dir', | |||||
| default=None, type=str) | |||||
| parser.add_argument('--error_step', help='Epoch steps to compute errors', | |||||
| default=5, type=int) | |||||
| parser.add_argument('--save_step', help='Epoch steps to save models', | |||||
| default=10, type=int) | |||||
| ##### Training Configurations ##### | |||||
| parser.add_argument('--epochs', help='Epochs', | |||||
| default=1000, type=int) | |||||
| parser.add_argument('--optimizer', help='Optimizer', | |||||
| choices=['sgd', 'lars'], | |||||
| default='lars', type=str) | |||||
| parser.add_argument('--lr_scheduler', help='Learning rate scheduler', | |||||
| choices=['step_decay', 'cosine'], | |||||
| default='cosine', type=str) | |||||
| parser.add_argument('--warmup', help='Warm-up epochs', | |||||
| default=10, type=int) | |||||
| parser.add_argument('--lr_init', help='Initial learning rate', | |||||
| default=1e-1, type=float) | |||||
| parser.add_argument('--weight_decay', help='Weight decay', | |||||
| default=1e-6, type=float) | |||||
| parser.add_argument('--batch_size', help='Batch size', | |||||
| default=128, type=int) | |||||
| parser.add_argument('--test_batch_size', help='Batch size for test loader', | |||||
| default=100, type=int) | |||||
| parser.add_argument('--blur_sigma', help='Distortion grade', | |||||
| default=2.0, type=float) | |||||
| parser.add_argument('--color_distort', help='Color distortion grade', | |||||
| default=0.5, type=float) | |||||
| parser.add_argument('--distortion_scale', help='Perspective distortion grade', | |||||
| default=0.6, type=float) | |||||
| parser.add_argument('--sharpness_factor', help='Sharpening or blurring factor of image. ' | |||||
| 'Can be any non negative number. 0 gives a blurred image, ' | |||||
| '1 gives the original image while 2 increases the sharpness ' | |||||
| 'by a factor of 2.', | |||||
| default=2, type=float) | |||||
| parser.add_argument('--noise_mean', help='mean', | |||||
| default=0, type=float) | |||||
| parser.add_argument('--noise_std', help='std', | |||||
| default=0.3, type=float) | |||||
| ##### Objective Configurations ##### | |||||
| parser.add_argument('--sim_lambda', help='Weight for SimCLR loss', | |||||
| default=1.0, type=float) | |||||
| parser.add_argument('--temperature', help='Temperature for similarity', | |||||
| default=0.5, type=float) | |||||
| ##### Evaluation Configurations ##### | |||||
| parser.add_argument("--ood_dataset", help='Datasets for OOD detection', | |||||
| default=None, nargs="*", type=str) | |||||
| parser.add_argument("--ood_score", help='score function for OOD detection', | |||||
| default=['norm_mean'], nargs="+", type=str) | |||||
| parser.add_argument("--ood_layer", help='layer for OOD scores', | |||||
| choices=['penultimate', 'simclr', 'shift'], | |||||
| default=['simclr', 'shift'], nargs="+", type=str) | |||||
| parser.add_argument("--ood_samples", help='number of samples to compute OOD score', | |||||
| default=1, type=int) | |||||
| parser.add_argument("--ood_batch_size", help='batch size to compute OOD score', | |||||
| default=100, type=int) | |||||
| parser.add_argument("--resize_factor", help='resize scale is sampled from [resize_factor, 1.0]', | |||||
| default=0.08, type=float) | |||||
| parser.add_argument("--resize_fix", help='resize scale is fixed to resize_factor (not (resize_factor, 1.0])', | |||||
| action='store_true') | |||||
| parser.add_argument("--print_score", help='print quantiles of ood score', | |||||
| action='store_true') | |||||
| parser.add_argument("--save_score", help='save ood score for plotting histogram', | |||||
| action='store_true') | |||||
| ##### Process configuration option ##### | |||||
| parser.add_argument("--proc_step", help='choose process to initiate.', | |||||
| choices=['eval', 'train'], | |||||
| default=None, type=str) | |||||
| parser.add_argument("--res", help='resolution of dataset', | |||||
| default="32px", type=str) | |||||
| if default: | |||||
| return parser.parse_args('') # empty string | |||||
| else: | |||||
| return parser.parse_args() |
+ 81
- 0
common/eval.py
View File
| from copy import deepcopy | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| from torch.utils.data import DataLoader | |||||
| from common.common import parse_args | |||||
| import models.classifier as C | |||||
| from datasets import get_dataset, get_superclass_list, get_subclass_dataset | |||||
| P = parse_args() | |||||
| ### Set torch device ### | |||||
| P.n_gpus = torch.cuda.device_count() | |||||
| assert P.n_gpus <= 1 # no multi GPU | |||||
| P.multi_gpu = False | |||||
| if torch.cuda.is_available(): | |||||
| torch.cuda.set_device(P.local_rank) | |||||
| device = torch.device(f"cuda" if torch.cuda.is_available() else "cpu") | |||||
| ### Initialize dataset ### | |||||
| ood_eval = P.mode == 'ood_pre' | |||||
| if P.dataset == 'imagenet' and ood_eval or P.dataset == 'CNMC' and ood_eval or P.dataset == 'CNMC_grayscale' and ood_eval: | |||||
| P.batch_size = 1 | |||||
| P.test_batch_size = 1 | |||||
| train_set, test_set, image_size, n_classes = get_dataset(P, dataset=P.dataset, eval=ood_eval) | |||||
| P.image_size = image_size | |||||
| P.n_classes = n_classes | |||||
| if P.one_class_idx is not None: | |||||
| cls_list = get_superclass_list(P.dataset) | |||||
| P.n_superclasses = len(cls_list) | |||||
| full_test_set = deepcopy(test_set) # test set of full classes | |||||
| train_set = get_subclass_dataset(train_set, classes=cls_list[P.one_class_idx]) | |||||
| test_set = get_subclass_dataset(test_set, classes=cls_list[P.one_class_idx]) | |||||
| kwargs = {'pin_memory': False, 'num_workers': 2} | |||||
| train_loader = DataLoader(train_set, shuffle=True, batch_size=P.batch_size, **kwargs) | |||||
| test_loader = DataLoader(test_set, shuffle=False, batch_size=P.test_batch_size, **kwargs) | |||||
| if P.ood_dataset is None: | |||||
| if P.one_class_idx is not None: | |||||
| P.ood_dataset = list(range(P.n_superclasses)) | |||||
| P.ood_dataset.pop(P.one_class_idx) | |||||
| elif P.dataset == 'cifar10': | |||||
| P.ood_dataset = ['svhn', 'lsun_resize', 'imagenet_resize', 'lsun_fix', 'imagenet_fix', 'cifar100', 'interp'] | |||||
| elif P.dataset == 'imagenet': | |||||
| P.ood_dataset = ['cub', 'stanford_dogs', 'flowers102', 'places365', 'food_101', 'caltech_256', 'dtd', 'pets'] | |||||
| ood_test_loader = dict() | |||||
| for ood in P.ood_dataset: | |||||
| if ood == 'interp': | |||||
| ood_test_loader[ood] = None # dummy loader | |||||
| continue | |||||
| if P.one_class_idx is not None: | |||||
| ood_test_set = get_subclass_dataset(full_test_set, classes=cls_list[ood]) | |||||
| ood = f'one_class_{ood}' # change save name | |||||
| else: | |||||
| ood_test_set = get_dataset(P, dataset=ood, test_only=True, image_size=P.image_size, eval=ood_eval) | |||||
| ood_test_loader[ood] = DataLoader(ood_test_set, shuffle=False, batch_size=P.test_batch_size, **kwargs) | |||||
| ### Initialize model ### | |||||
| simclr_aug = C.get_simclr_augmentation(P, image_size=P.image_size).to(device) | |||||
| P.shift_trans, P.K_shift = C.get_shift_module(P, eval=True) | |||||
| P.shift_trans = P.shift_trans.to(device) | |||||
| model = C.get_classifier(P.model, n_classes=P.n_classes).to(device) | |||||
| model = C.get_shift_classifer(model, P.K_shift).to(device) | |||||
| criterion = nn.CrossEntropyLoss().to(device) | |||||
| if P.load_path is not None: | |||||
| checkpoint = torch.load(P.load_path) | |||||
| model.load_state_dict(checkpoint, strict=not P.no_strict) |
+ 148
- 0
common/train.py
View File
| from copy import deepcopy | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import torch.optim as optim | |||||
| import torch.optim.lr_scheduler as lr_scheduler | |||||
| from torch.utils.data import DataLoader | |||||
| from common.common import parse_args | |||||
| import models.classifier as C | |||||
| from datasets import get_dataset, get_superclass_list, get_subclass_dataset | |||||
| from utils.utils import load_checkpoint | |||||
| P = parse_args() | |||||
| ### Set torch device ### | |||||
| if torch.cuda.is_available(): | |||||
| torch.cuda.set_device(P.local_rank) | |||||
| device = torch.device(f"cuda" if torch.cuda.is_available() else "cpu") | |||||
| P.n_gpus = torch.cuda.device_count() | |||||
| if P.n_gpus > 1: | |||||
| import apex | |||||
| import torch.distributed as dist | |||||
| from torch.utils.data.distributed import DistributedSampler | |||||
| P.multi_gpu = True | |||||
| torch.distributed.init_process_group( | |||||
| 'nccl', | |||||
| init_method='env://', | |||||
| world_size=P.n_gpus, | |||||
| rank=P.local_rank, | |||||
| ) | |||||
| else: | |||||
| P.multi_gpu = False | |||||
| ### only use one ood_layer while training | |||||
| P.ood_layer = P.ood_layer[0] | |||||
| ### Initialize dataset ### | |||||
| train_set, test_set, image_size, n_classes = get_dataset(P, dataset=P.dataset) | |||||
| P.image_size = image_size | |||||
| P.n_classes = n_classes | |||||
| if P.one_class_idx is not None: | |||||
| cls_list = get_superclass_list(P.dataset) | |||||
| P.n_superclasses = len(cls_list) | |||||
| full_test_set = deepcopy(test_set) # test set of full classes | |||||
| train_set = get_subclass_dataset(train_set, classes=cls_list[P.one_class_idx]) | |||||
| test_set = get_subclass_dataset(test_set, classes=cls_list[P.one_class_idx]) | |||||
| kwargs = {'pin_memory': False, 'num_workers': 2} | |||||
| if P.multi_gpu: | |||||
| train_sampler = DistributedSampler(train_set, num_replicas=P.n_gpus, rank=P.local_rank) | |||||
| test_sampler = DistributedSampler(test_set, num_replicas=P.n_gpus, rank=P.local_rank) | |||||
| train_loader = DataLoader(train_set, sampler=train_sampler, batch_size=P.batch_size, **kwargs) | |||||
| test_loader = DataLoader(test_set, sampler=test_sampler, batch_size=P.test_batch_size, **kwargs) | |||||
| else: | |||||
| train_loader = DataLoader(train_set, shuffle=True, batch_size=P.batch_size, **kwargs) | |||||
| test_loader = DataLoader(test_set, shuffle=False, batch_size=P.test_batch_size, **kwargs) | |||||
| if P.ood_dataset is None: | |||||
| if P.one_class_idx is not None: | |||||
| P.ood_dataset = list(range(P.n_superclasses)) | |||||
| P.ood_dataset.pop(P.one_class_idx) | |||||
| elif P.dataset == 'cifar10': | |||||
| P.ood_dataset = ['svhn', 'lsun_resize', 'imagenet_resize', 'lsun_fix', 'imagenet_fix', 'cifar100', 'interp'] | |||||
| elif P.dataset == 'imagenet': | |||||
| P.ood_dataset = ['cub', 'stanford_dogs', 'flowers102'] | |||||
| ood_test_loader = dict() | |||||
| for ood in P.ood_dataset: | |||||
| if ood == 'interp': | |||||
| ood_test_loader[ood] = None # dummy loader | |||||
| continue | |||||
| if P.one_class_idx is not None: | |||||
| ood_test_set = get_subclass_dataset(full_test_set, classes=cls_list[ood]) | |||||
| ood = f'one_class_{ood}' # change save name | |||||
| else: | |||||
| ood_test_set = get_dataset(P, dataset=ood, test_only=True, image_size=P.image_size) | |||||
| if P.multi_gpu: | |||||
| ood_sampler = DistributedSampler(ood_test_set, num_replicas=P.n_gpus, rank=P.local_rank) | |||||
| ood_test_loader[ood] = DataLoader(ood_test_set, sampler=ood_sampler, batch_size=P.test_batch_size, **kwargs) | |||||
| else: | |||||
| ood_test_loader[ood] = DataLoader(ood_test_set, shuffle=False, batch_size=P.test_batch_size, **kwargs) | |||||
| ### Initialize model ### | |||||
| simclr_aug = C.get_simclr_augmentation(P, image_size=P.image_size).to(device) | |||||
| P.shift_trans, P.K_shift = C.get_shift_module(P, eval=True) | |||||
| P.shift_trans = P.shift_trans.to(device) | |||||
| model = C.get_classifier(P.model, n_classes=P.n_classes).to(device) | |||||
| model = C.get_shift_classifer(model, P.K_shift).to(device) | |||||
| criterion = nn.CrossEntropyLoss().to(device) | |||||
| if P.optimizer == 'sgd': | |||||
| optimizer = optim.SGD(model.parameters(), lr=P.lr_init, momentum=0.9, weight_decay=P.weight_decay) | |||||
| lr_decay_gamma = 0.1 | |||||
| elif P.optimizer == 'lars': | |||||
| from torchlars import LARS | |||||
| base_optimizer = optim.SGD(model.parameters(), lr=P.lr_init, momentum=0.9, weight_decay=P.weight_decay) | |||||
| optimizer = LARS(base_optimizer, eps=1e-8, trust_coef=0.001) | |||||
| lr_decay_gamma = 0.1 | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| if P.lr_scheduler == 'cosine': | |||||
| scheduler = lr_scheduler.CosineAnnealingLR(optimizer, P.epochs) | |||||
| elif P.lr_scheduler == 'step_decay': | |||||
| milestones = [int(0.5 * P.epochs), int(0.75 * P.epochs)] | |||||
| scheduler = lr_scheduler.MultiStepLR(optimizer, gamma=lr_decay_gamma, milestones=milestones) | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| from training.scheduler import GradualWarmupScheduler | |||||
| scheduler_warmup = GradualWarmupScheduler(optimizer, multiplier=10.0, total_epoch=P.warmup, after_scheduler=scheduler) | |||||
| if P.resume_path is not None: | |||||
| resume = True | |||||
| model_state, optim_state, config = load_checkpoint(P.resume_path, mode='last') | |||||
| model.load_state_dict(model_state, strict=not P.no_strict) | |||||
| optimizer.load_state_dict(optim_state) | |||||
| start_epoch = config['epoch'] | |||||
| best = config['best'] | |||||
| error = 100.0 | |||||
| else: | |||||
| resume = False | |||||
| start_epoch = 1 | |||||
| best = 100.0 | |||||
| error = 100.0 | |||||
| if P.mode == 'sup_linear' or P.mode == 'sup_CSI_linear': | |||||
| assert P.load_path is not None | |||||
| checkpoint = torch.load(P.load_path) | |||||
| model.load_state_dict(checkpoint, strict=not P.no_strict) | |||||
| if P.multi_gpu: | |||||
| simclr_aug = apex.parallel.DistributedDataParallel(simclr_aug, delay_allreduce=True) | |||||
| model = apex.parallel.convert_syncbn_model(model) | |||||
| model = apex.parallel.DistributedDataParallel(model, delay_allreduce=True) |
BIN
data/ImageNet_FIX.tar.gz
View File
BIN
data/Imagenet_resize.tar.gz
View File
BIN
data/LSUN_FIX.tar.gz
View File
BIN
data/LSUN_resize.tar.gz
View File
+ 2
- 0
datasets/__init__.py
View File
| from datasets.datasets import get_dataset, get_superclass_list, get_subclass_dataset | |||||
BIN
datasets/__pycache__/__init__.cpython-36.pyc
View File
BIN
datasets/__pycache__/__init__.cpython-37.pyc
View File
BIN
datasets/__pycache__/datasets.cpython-36.pyc
View File
BIN
datasets/__pycache__/datasets.cpython-37.pyc
View File
+ 0
- 0
datasets/__pycache__/datasets.cpython-37.pyc.2427217203392
View File
BIN
datasets/__pycache__/postprocess_data.cpython-36.pyc
View File
BIN
datasets/__pycache__/postprocess_data.cpython-37.pyc
View File
BIN
datasets/__pycache__/prepare_data.cpython-36.pyc
View File
BIN
datasets/__pycache__/prepare_data.cpython-37.pyc
View File
+ 361
- 0
datasets/datasets.py
View File
| import os | |||||
| import numpy as np | |||||
| import torch | |||||
| from torch.utils.data.dataset import Subset | |||||
| from torchvision import datasets, transforms | |||||
| from utils.utils import set_random_seed | |||||
| DATA_PATH = '~/data/' | |||||
| IMAGENET_PATH = '~/data/ImageNet' | |||||
| CNMC_PATH = r'~/data/CSI/CNMC_orig' | |||||
| CNMC_GRAY_PATH = r'~/data/CSI/CNMC_orig_gray' | |||||
| CNMC_ROT4_PATH = r'~/data/CSI/CNMC_rotated_4' | |||||
| CIFAR10_SUPERCLASS = list(range(10)) # one class | |||||
| IMAGENET_SUPERCLASS = list(range(30)) # one class | |||||
| CNMC_SUPERCLASS = list(range(2)) # one class | |||||
| STD_RES = 450 | |||||
| STD_CENTER_CROP = 300 | |||||
| CIFAR100_SUPERCLASS = [ | |||||
| [4, 31, 55, 72, 95], | |||||
| [1, 33, 67, 73, 91], | |||||
| [54, 62, 70, 82, 92], | |||||
| [9, 10, 16, 29, 61], | |||||
| [0, 51, 53, 57, 83], | |||||
| [22, 25, 40, 86, 87], | |||||
| [5, 20, 26, 84, 94], | |||||
| [6, 7, 14, 18, 24], | |||||
| [3, 42, 43, 88, 97], | |||||
| [12, 17, 38, 68, 76], | |||||
| [23, 34, 49, 60, 71], | |||||
| [15, 19, 21, 32, 39], | |||||
| [35, 63, 64, 66, 75], | |||||
| [27, 45, 77, 79, 99], | |||||
| [2, 11, 36, 46, 98], | |||||
| [28, 30, 44, 78, 93], | |||||
| [37, 50, 65, 74, 80], | |||||
| [47, 52, 56, 59, 96], | |||||
| [8, 13, 48, 58, 90], | |||||
| [41, 69, 81, 85, 89], | |||||
| ] | |||||
| class MultiDataTransform(object): | |||||
| def __init__(self, transform): | |||||
| self.transform1 = transform | |||||
| self.transform2 = transform | |||||
| def __call__(self, sample): | |||||
| x1 = self.transform1(sample) | |||||
| x2 = self.transform2(sample) | |||||
| return x1, x2 | |||||
| class MultiDataTransformList(object): | |||||
| def __init__(self, transform, clean_trasform, sample_num): | |||||
| self.transform = transform | |||||
| self.clean_transform = clean_trasform | |||||
| self.sample_num = sample_num | |||||
| def __call__(self, sample): | |||||
| set_random_seed(0) | |||||
| sample_list = [] | |||||
| for i in range(self.sample_num): | |||||
| sample_list.append(self.transform(sample)) | |||||
| return sample_list, self.clean_transform(sample) | |||||
| def get_transform(image_size=None): | |||||
| # Note: data augmentation is implemented in the layers | |||||
| # Hence, we only define the identity transformation here | |||||
| if image_size: # use pre-specified image size | |||||
| train_transform = transforms.Compose([ | |||||
| transforms.Resize((image_size[0], image_size[1])), | |||||
| transforms.RandomHorizontalFlip(), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| test_transform = transforms.Compose([ | |||||
| transforms.Resize((image_size[0], image_size[1])), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| else: # use default image size | |||||
| train_transform = transforms.Compose([ | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| test_transform = transforms.ToTensor() | |||||
| return train_transform, test_transform | |||||
| def get_subset_with_len(dataset, length, shuffle=False): | |||||
| set_random_seed(0) | |||||
| dataset_size = len(dataset) | |||||
| index = np.arange(dataset_size) | |||||
| if shuffle: | |||||
| np.random.shuffle(index) | |||||
| index = torch.from_numpy(index[0:length]) | |||||
| subset = Subset(dataset, index) | |||||
| assert len(subset) == length | |||||
| return subset | |||||
| def get_transform_imagenet(): | |||||
| train_transform = transforms.Compose([ | |||||
| transforms.Resize(256), | |||||
| transforms.RandomResizedCrop(224), | |||||
| transforms.RandomHorizontalFlip(), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| test_transform = transforms.Compose([ | |||||
| transforms.Resize(256), | |||||
| transforms.CenterCrop(224), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| train_transform = MultiDataTransform(train_transform) | |||||
| return train_transform, test_transform | |||||
| def get_transform_cnmc(res, center_crop_size): | |||||
| train_transform = transforms.Compose([ | |||||
| transforms.Resize(res), | |||||
| transforms.CenterCrop(center_crop_size), | |||||
| transforms.RandomVerticalFlip(), | |||||
| transforms.RandomHorizontalFlip(), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| test_transform = transforms.Compose([ | |||||
| transforms.Resize(res), | |||||
| transforms.CenterCrop(center_crop_size), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| train_transform = MultiDataTransform(train_transform) | |||||
| return train_transform, test_transform | |||||
| def get_dataset(P, dataset, test_only=False, image_size=None, download=False, eval=False): | |||||
| if P.res != '': | |||||
| res = int(P.res.replace('px', '')) | |||||
| size_factor = int(STD_RES/res) # always remove same portion | |||||
| center_crop_size = int(STD_CENTER_CROP/size_factor) # remove black border | |||||
| if dataset in ['CNMC', 'CNMC_grayscale', 'CNMC_ROT4_PATH']: | |||||
| if eval: | |||||
| train_transform, test_transform = get_simclr_eval_transform_cnmc(P.ood_samples, | |||||
| P.resize_factor, P.resize_fix, res, center_crop_size) | |||||
| else: | |||||
| train_transform, test_transform = get_transform_cnmc(res, center_crop_size) | |||||
| elif dataset in ['imagenet', 'cub', 'stanford_dogs', 'flowers102', | |||||
| 'places365', 'food_101', 'caltech_256', 'dtd', 'pets']: | |||||
| if eval: | |||||
| train_transform, test_transform = get_simclr_eval_transform_imagenet(P.ood_samples, | |||||
| P.resize_factor, P.resize_fix) | |||||
| else: | |||||
| train_transform, test_transform = get_transform_imagenet() | |||||
| else: | |||||
| train_transform, test_transform = get_transform(image_size=image_size) | |||||
| if dataset == 'CNMC': | |||||
| image_size = (center_crop_size, center_crop_size, 3) #original 450,450,3 | |||||
| n_classes = 2 | |||||
| train_dir = os.path.join(CNMC_PATH, '0_training') | |||||
| test_dir = os.path.join(CNMC_PATH, '1_validation') | |||||
| train_set = datasets.ImageFolder(train_dir, transform=train_transform) | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| elif dataset == 'CNMC_grayscale': | |||||
| image_size = (center_crop_size, center_crop_size, 3) #original 450,450,3 | |||||
| n_classes = 2 | |||||
| train_dir = os.path.join(CNMC_GRAY_PATH, '0_training') | |||||
| test_dir = os.path.join(CNMC_GRAY_PATH, '1_validation') | |||||
| train_set = datasets.ImageFolder(train_dir, transform=train_transform) | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| elif dataset == 'cifar10': | |||||
| image_size = (32, 32, 3) | |||||
| n_classes = 10 | |||||
| train_set = datasets.CIFAR10(DATA_PATH, train=True, download=download, transform=train_transform) | |||||
| test_set = datasets.CIFAR10(DATA_PATH, train=False, download=download, transform=test_transform) | |||||
| elif dataset == 'cifar100': | |||||
| image_size = (32, 32, 3) | |||||
| n_classes = 100 | |||||
| train_set = datasets.CIFAR100(DATA_PATH, train=True, download=download, transform=train_transform) | |||||
| test_set = datasets.CIFAR100(DATA_PATH, train=False, download=download, transform=test_transform) | |||||
| elif dataset == 'svhn': | |||||
| assert test_only and image_size is not None | |||||
| test_set = datasets.SVHN(DATA_PATH, split='test', download=download, transform=test_transform) | |||||
| elif dataset == 'lsun_resize': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'LSUN_resize') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| elif dataset == 'lsun_fix': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'LSUN_fix') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| elif dataset == 'imagenet_resize': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'Imagenet_resize') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| elif dataset == 'imagenet_fix': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'Imagenet_fix') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| elif dataset == 'imagenet': | |||||
| image_size = (224, 224, 3) | |||||
| n_classes = 30 | |||||
| train_dir = os.path.join(IMAGENET_PATH, 'one_class_train') | |||||
| test_dir = os.path.join(IMAGENET_PATH, 'one_class_test') | |||||
| train_set = datasets.ImageFolder(train_dir, transform=train_transform) | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| elif dataset == 'stanford_dogs': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'stanford_dogs') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| elif dataset == 'cub': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'cub200') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| elif dataset == 'flowers102': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'flowers102') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| elif dataset == 'places365': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'places365') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| elif dataset == 'food_101': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'food-101', 'images') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| elif dataset == 'caltech_256': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'caltech-256') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| elif dataset == 'dtd': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'dtd', 'images') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| elif dataset == 'pets': | |||||
| assert test_only and image_size is not None | |||||
| test_dir = os.path.join(DATA_PATH, 'pets') | |||||
| test_set = datasets.ImageFolder(test_dir, transform=test_transform) | |||||
| test_set = get_subset_with_len(test_set, length=3000, shuffle=True) | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| if test_only: | |||||
| return test_set | |||||
| else: | |||||
| return train_set, test_set, image_size, n_classes | |||||
| def get_superclass_list(dataset): | |||||
| if dataset == 'CNMC': | |||||
| return CNMC_SUPERCLASS | |||||
| if dataset == 'CNMC_grayscale': | |||||
| return CNMC_SUPERCLASS | |||||
| elif dataset == 'cifar10': | |||||
| return CIFAR10_SUPERCLASS | |||||
| elif dataset == 'cifar100': | |||||
| return CIFAR100_SUPERCLASS | |||||
| elif dataset == 'imagenet': | |||||
| return IMAGENET_SUPERCLASS | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| def get_subclass_dataset(dataset, classes): | |||||
| if not isinstance(classes, list): | |||||
| classes = [classes] | |||||
| indices = [] | |||||
| for idx, tgt in enumerate(dataset.targets): | |||||
| if tgt in classes: | |||||
| indices.append(idx) | |||||
| dataset = Subset(dataset, indices) | |||||
| return dataset | |||||
| def get_simclr_eval_transform_imagenet(sample_num, resize_factor, resize_fix): | |||||
| resize_scale = (resize_factor, 1.0) # resize scaling factor | |||||
| if resize_fix: # if resize_fix is True, use same scale | |||||
| resize_scale = (resize_factor, resize_factor) | |||||
| transform = transforms.Compose([ | |||||
| transforms.Resize(256), | |||||
| transforms.RandomResizedCrop(224, scale=resize_scale), | |||||
| transforms.RandomHorizontalFlip(), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| clean_trasform = transforms.Compose([ | |||||
| transforms.Resize(256), | |||||
| transforms.CenterCrop(224), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| transform = MultiDataTransformList(transform, clean_trasform, sample_num) | |||||
| return transform, transform | |||||
| def get_simclr_eval_transform_cnmc(sample_num, resize_factor, resize_fix, res, center_crop_size): | |||||
| resize_scale = (resize_factor, 1.0) # resize scaling factor | |||||
| if resize_fix: # if resize_fix is True, use same scale | |||||
| resize_scale = (resize_factor, resize_factor) | |||||
| transform = transforms.Compose([ | |||||
| transforms.Resize(res), | |||||
| transforms.CenterCrop(center_crop_size), | |||||
| transforms.RandomVerticalFlip(), | |||||
| transforms.RandomHorizontalFlip(), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| clean_trasform = transforms.Compose([ | |||||
| transforms.Resize(res), | |||||
| transforms.CenterCrop(center_crop_size), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| transform = MultiDataTransformList(transform, clean_trasform, sample_num) | |||||
| return transform, transform | |||||
+ 66
- 0
datasets/imagenet_fix_preprocess.py
View File
| import os | |||||
| import time | |||||
| import random | |||||
| import cv2 | |||||
| import numpy as np | |||||
| import torch | |||||
| import torch.nn.functional as F | |||||
| from torchvision import datasets, transforms | |||||
| from torch.utils.data import DataLoader | |||||
| from torchvision.utils import save_image | |||||
| from datasets import get_subclass_dataset | |||||
| def set_random_seed(seed): | |||||
| random.seed(seed) | |||||
| np.random.seed(seed) | |||||
| torch.manual_seed(seed) | |||||
| torch.cuda.manual_seed(seed) | |||||
| IMAGENET_PATH = '~/data/ImageNet' | |||||
| check = time.time() | |||||
| transform = transforms.Compose([ | |||||
| transforms.Resize(256), | |||||
| transforms.CenterCrop(256), | |||||
| transforms.Resize(32), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| # remove airliner(1), ambulance(2), parking_meter(18), schooner(22) since similar class exist in CIFAR-10 | |||||
| class_idx_list = list(range(30)) | |||||
| remove_idx_list = [1, 2, 18, 22] | |||||
| for remove_idx in remove_idx_list: | |||||
| class_idx_list.remove(remove_idx) | |||||
| set_random_seed(0) | |||||
| train_dir = os.path.join(IMAGENET_PATH, 'one_class_train') | |||||
| Imagenet_set = datasets.ImageFolder(train_dir, transform=transform) | |||||
| Imagenet_set = get_subclass_dataset(Imagenet_set, class_idx_list) | |||||
| Imagenet_dataloader = DataLoader(Imagenet_set, batch_size=100, shuffle=True, pin_memory=False) | |||||
| total_test_image = None | |||||
| for n, (test_image, target) in enumerate(Imagenet_dataloader): | |||||
| if n == 0: | |||||
| total_test_image = test_image | |||||
| else: | |||||
| total_test_image = torch.cat((total_test_image, test_image), dim=0).cpu() | |||||
| if total_test_image.size(0) >= 10000: | |||||
| break | |||||
| print (f'Preprocessing time {time.time()-check}') | |||||
| if not os.path.exists('./Imagenet_fix'): | |||||
| os.mkdir('./Imagenet_fix') | |||||
| check = time.time() | |||||
| for i in range(10000): | |||||
| save_image(total_test_image[i], f'Imagenet_fix/correct_resize_{i}.png') | |||||
| print (f'Saving time {time.time()-check}') | |||||
+ 61
- 0
datasets/lsun_fix_preprocess.py
View File
| import os | |||||
| import time | |||||
| import random | |||||
| import numpy as np | |||||
| import torch | |||||
| from torchvision import datasets, transforms | |||||
| from torch.utils.data import DataLoader | |||||
| from torchvision.utils import save_image | |||||
| def set_random_seed(seed): | |||||
| random.seed(seed) | |||||
| np.random.seed(seed) | |||||
| torch.manual_seed(seed) | |||||
| torch.cuda.manual_seed(seed) | |||||
| check = time.time() | |||||
| transform = transforms.Compose([ | |||||
| transforms.Resize(256), | |||||
| transforms.CenterCrop(256), | |||||
| transforms.Resize(32), | |||||
| transforms.ToTensor(), | |||||
| ]) | |||||
| set_random_seed(0) | |||||
| LSUN_class_list = ['bedroom', 'bridge', 'church_outdoor', 'classroom', | |||||
| 'conference_room', 'dining_room', 'kitchen', 'living_room', 'restaurant', 'tower'] | |||||
| total_test_image_all_class = [] | |||||
| for LSUN_class in LSUN_class_list: | |||||
| LSUN_set = datasets.LSUN('~/data/lsun/', classes=LSUN_class + '_train', transform=transform) | |||||
| LSUN_loader = DataLoader(LSUN_set, batch_size=100, shuffle=True, pin_memory=False) | |||||
| total_test_image = None | |||||
| for n, (test_image, _) in enumerate(LSUN_loader): | |||||
| if n == 0: | |||||
| total_test_image = test_image | |||||
| else: | |||||
| total_test_image = torch.cat((total_test_image, test_image), dim=0).cpu() | |||||
| if total_test_image.size(0) >= 1000: | |||||
| break | |||||
| total_test_image_all_class.append(total_test_image) | |||||
| total_test_image_all_class = torch.cat(total_test_image_all_class, dim=0) | |||||
| print (f'Preprocessing time {time.time()-check}') | |||||
| if not os.path.exists('./LSUN_fix'): | |||||
| os.mkdir('./LSUN_fix') | |||||
| check = time.time() | |||||
| for i in range(10000): | |||||
| save_image(total_test_image_all_class[i], f'LSUN_fix/correct_resize_{i}.png') | |||||
| print (f'Saving time {time.time()-check}') | |||||
+ 37
- 0
datasets/postprocess_data.py
View File
| import re | |||||
| import matplotlib.pyplot as plt | |||||
| PATH = r'C:\Users\feokt\PycharmProjects\CSI\CSI\logs' | |||||
| def postprocess_data(log: list): | |||||
| for pth in log: | |||||
| loss_sim = [] | |||||
| loss_shift = [] | |||||
| with open(PATH + pth) as f: | |||||
| lines = f.readlines() | |||||
| for line in lines: | |||||
| # line = '[2022-01-31 20:40:23.947855] [DONE] [Time 0.179] [Data 0.583] [LossC 0.000000] [LossSim 4.024234] [LossShift 0.065126]' | |||||
| part = re.search('\[DONE\]', line) | |||||
| if part is not None: | |||||
| l_sim = re.search('(\[LossSim.[0-9]*.[0-9]*\])', line).group() | |||||
| if l_sim is not None: | |||||
| loss_sim.append(float(re.search('(\s[0-9].*[0-9])', l_sim).group())) | |||||
| l_shift = re.search('(\[LossShift.[0-9]*.[0-9]*\])', line).group() | |||||
| if l_shift is not None: | |||||
| loss_shift.append(float(re.search('(\s[0-9].*[0-9])', l_shift).group())) | |||||
| loss = [loss_sim[i] + loss_shift[i] for i in range(len(loss_sim))] | |||||
| plt.ylabel("loss") | |||||
| plt.xlabel("epoch") | |||||
| plt.title("Loss over epochs") | |||||
| plt.plot(list(range(1, 101)), loss) | |||||
| for idx in range(len(log)): | |||||
| log[idx] = log[idx][38:] | |||||
| plt.legend(log) | |||||
| plt.grid() | |||||
| #plt.plot(list(range(1, 101)), loss_sim) | |||||
| #plt.plot(list(range(1, 101)), loss_shift) | |||||
| plt.show() | |||||
+ 196
- 0
datasets/prepare_data.py
View File
| import csv | |||||
| import os | |||||
| from PIL import Image | |||||
| from torchvision import transforms | |||||
| from torchvision.utils import save_image | |||||
| import torch | |||||
| def transform_image(img_in, target_dir, transformation, suffix): | |||||
| """ | |||||
| Transforms an image according to provided transformation. | |||||
| Parameters: | |||||
| img_in (path): Image to transform | |||||
| target_dir (path): Destination path | |||||
| transformation (callable): Transformation to be applied | |||||
| suffix (str): Suffix of resulting image. | |||||
| Returns: | |||||
| binary_sum (str): Binary string of the sum of a and b | |||||
| """ | |||||
| if suffix == 'rot': | |||||
| im = Image.open(img_in) | |||||
| im = im.rotate(270) | |||||
| tensor = transforms.ToTensor()(im) | |||||
| save_image(tensor, target_dir + os.sep + suffix + '.jpg') | |||||
| elif suffix == 'sobel': | |||||
| im = Image.open(img_in) | |||||
| tensor = transforms.ToTensor()(im) | |||||
| sobel_filter = torch.tensor([[1., 2., 1.], [0., 0., 0.], [-1., -2., -1.]]) | |||||
| f = sobel_filter.expand(1, 3, 3, 3) | |||||
| tensor = torch.conv2d(tensor, f, stride=1, padding=1 ) | |||||
| save_image(tensor, target_dir + os.sep + suffix + '.jpg') | |||||
| elif suffix == 'noise': | |||||
| im = Image.open(img_in) | |||||
| tensor = transforms.ToTensor()(im) | |||||
| tensor = tensor + (torch.randn(tensor.size()) * 0.2 + 0) | |||||
| save_image(tensor, target_dir + os.sep + suffix + '.jpg') | |||||
| elif suffix == 'cutout': | |||||
| print("asd") | |||||
| else: | |||||
| im = Image.open(img_in) | |||||
| im_trans = transformation(im) | |||||
| im_trans.save(target_dir + os.sep + suffix + '.jpg') | |||||
| def sort_and_rename_images(excel_path: str): | |||||
| """Renames images and sorts them according to csv.""" | |||||
| base_dir = excel_path.rsplit(os.sep, 1)[0] | |||||
| dir_all = base_dir + os.sep + 'all' | |||||
| if not os.path.isdir(dir_all): | |||||
| os.mkdir(dir_all) | |||||
| dir_hem = base_dir + os.sep + 'hem' | |||||
| if not os.path.isdir(dir_hem): | |||||
| os.mkdir(dir_hem) | |||||
| with open(excel_path, mode='r') as file: | |||||
| csv_file = csv.reader(file) | |||||
| for lines in csv_file: | |||||
| print(lines) | |||||
| if lines[2] == '1': | |||||
| os.rename(base_dir + os.sep + lines[1], dir_all + os.sep + lines[0]) | |||||
| elif lines[2] == '0': | |||||
| os.rename(base_dir + os.sep + lines[1], dir_hem + os.sep + lines[0]) | |||||
| def drop_color_channels(source_dir, target_dir, rgb): | |||||
| """Rotates all images in in source dir.""" | |||||
| if rgb == 0: | |||||
| suffix = "red_only" | |||||
| drop_1 = 1 | |||||
| drop_2 = 2 | |||||
| elif rgb == 1: | |||||
| suffix = "green_only" | |||||
| drop_1 = 0 | |||||
| drop_2 = 2 | |||||
| elif rgb == 2: | |||||
| suffix = "blue_only" | |||||
| drop_1 = 0 | |||||
| drop_2 = 1 | |||||
| elif rgb == 3: | |||||
| suffix = "no_red" | |||||
| drop_1 = 0 | |||||
| elif rgb == 4: | |||||
| suffix = "no_green" | |||||
| drop_1 = 1 | |||||
| elif rgb == 5: | |||||
| suffix = "no_blue" | |||||
| drop_1 = 2 | |||||
| else: | |||||
| suffix = "" | |||||
| print("Invalid RGB-channel") | |||||
| if suffix != "": | |||||
| dirs = os.listdir(source_dir) | |||||
| for item in dirs: | |||||
| if os.path.isfile(source_dir + os.sep + item): | |||||
| im = Image.open(source_dir + os.sep + item) | |||||
| tensor = transforms.ToTensor()(im) | |||||
| tensor[drop_1, :, :] = 0 | |||||
| if rgb < 3: | |||||
| tensor[drop_2, :, :] = 0 | |||||
| save_image(tensor, target_dir + os.sep + item, 'bmp') | |||||
| def rotate_images(target_dir, source_dir, rotate, theta): | |||||
| """Rotates all images in in source dir.""" | |||||
| dirs = os.listdir(source_dir) | |||||
| for item in dirs: | |||||
| if os.path.isfile(source_dir + os.sep + item): | |||||
| for i in range(0, rotate): | |||||
| im = Image.open(source_dir + os.sep + item) | |||||
| im = im.rotate(i*theta) | |||||
| tensor = transforms.ToTensor()(im) | |||||
| save_image(tensor, target_dir + os.sep + str(i) + '_' + item, 'bmp') | |||||
| def grayscale_image(source_dir, target_dir): | |||||
| """Grayscale transforms all images in path.""" | |||||
| t = transforms.Grayscale() | |||||
| dirs = os.listdir(source_dir) | |||||
| if not os.path.isdir(target_dir): | |||||
| os.mkdir(target_dir) | |||||
| for item in dirs: | |||||
| if os.path.isfile(source_dir + os.sep + item): | |||||
| im = Image.open(source_dir + os.sep + item).convert('RGB') | |||||
| im_resize = t(im) | |||||
| tensor = transforms.ToTensor()(im_resize) | |||||
| padding = torch.zeros(1, tensor.shape[1], tensor.shape[2]) | |||||
| tensor = torch.cat((tensor, padding), 0) | |||||
| im_resize.save(target_dir + os.sep + item, 'bmp') | |||||
| def resize(source_dir): | |||||
| """Rotates all images in in source dir.""" | |||||
| t = transforms.Compose([transforms.Resize((128, 128))]) | |||||
| dirs = os.listdir(source_dir) | |||||
| target_dir = source_dir + os.sep + 'resized' | |||||
| if not os.path.isdir(target_dir): | |||||
| os.mkdir(target_dir) | |||||
| for item in dirs: | |||||
| if os.path.isfile(source_dir + os.sep + item): | |||||
| im = Image.open(source_dir + os.sep + item) | |||||
| im_resize = t(im) | |||||
| im_resize.save(source_dir + os.sep + 'resized' + os.sep + item, 'bmp') | |||||
| def crop_image(source_dir): | |||||
| """Center Crops all images in path.""" | |||||
| t = transforms.CenterCrop((224, 224)) | |||||
| dirs = os.listdir(source_dir) | |||||
| target_dir = source_dir + os.sep + 'cropped' | |||||
| if not os.path.isdir(target_dir): | |||||
| os.mkdir(target_dir) | |||||
| for item in dirs: | |||||
| if os.path.isfile(source_dir + os.sep + item): | |||||
| im = Image.open(source_dir + os.sep + item) | |||||
| im_resize = t(im, ) | |||||
| im_resize.save(source_dir + os.sep + 'cropped' + os.sep + item, 'bmp') | |||||
| def mk_dirs(target_dir): | |||||
| dir_0 = target_dir + r"\fold_0" | |||||
| dir_1 = target_dir + r"\fold_1" | |||||
| dir_2 = target_dir + r"\fold_2" | |||||
| dir_3 = target_dir + r"\phase2" | |||||
| dir_4 = target_dir + r"\phase3" | |||||
| dir_0_all = dir_0 + r"\all" | |||||
| dir_0_hem = dir_0 + r"\hem" | |||||
| dir_1_all = dir_1 + r"\all" | |||||
| dir_1_hem = dir_1 + r"\hem" | |||||
| dir_2_all = dir_2 + r"\all" | |||||
| dir_2_hem = dir_2 + r"\hem" | |||||
| if not os.path.isdir(dir_0): | |||||
| os.mkdir(dir_0) | |||||
| if not os.path.isdir(dir_1): | |||||
| os.mkdir(dir_1) | |||||
| if not os.path.isdir(dir_2): | |||||
| os.mkdir(dir_2) | |||||
| if not os.path.isdir(dir_3): | |||||
| os.mkdir(dir_3) | |||||
| if not os.path.isdir(dir_4): | |||||
| os.mkdir(dir_4) | |||||
| if not os.path.isdir(dir_0_all): | |||||
| os.mkdir(dir_0_all) | |||||
| if not os.path.isdir(dir_0_hem): | |||||
| os.mkdir(dir_0_hem) | |||||
| if not os.path.isdir(dir_1_all): | |||||
| os.mkdir(dir_1_all) | |||||
| if not os.path.isdir(dir_1_hem): | |||||
| os.mkdir(dir_1_hem) | |||||
| if not os.path.isdir(dir_2_all): | |||||
| os.mkdir(dir_2_all) | |||||
| if not os.path.isdir(dir_2_hem): | |||||
| os.mkdir(dir_2_hem) | |||||
| return dir_0_all, dir_0_hem, dir_1_all, dir_1_hem, dir_2_all, dir_2_hem, dir_3, dir_4 |
+ 4691
- 0
eval.ipynb
File diff suppressed because it is too large
View File
+ 57
- 0
eval.py
View File
| from common.eval import * | |||||
| def main(): | |||||
| model.eval() | |||||
| if P.mode == 'test_acc': | |||||
| from evals import test_classifier | |||||
| with torch.no_grad(): | |||||
| error = test_classifier(P, model, test_loader, 0, logger=None) | |||||
| elif P.mode == 'test_marginalized_acc': | |||||
| from evals import test_classifier | |||||
| with torch.no_grad(): | |||||
| error = test_classifier(P, model, test_loader, 0, marginal=True, logger=None) | |||||
| elif P.mode in ['ood', 'ood_pre']: | |||||
| if P.mode == 'ood': | |||||
| from evals import eval_ood_detection | |||||
| else: | |||||
| from evals.ood_pre import eval_ood_detection | |||||
| with torch.no_grad(): | |||||
| auroc_dict = eval_ood_detection(P, model, test_loader, ood_test_loader, P.ood_score, | |||||
| train_loader=train_loader, simclr_aug=simclr_aug) | |||||
| if P.one_class_idx is not None: | |||||
| mean_dict = dict() | |||||
| for ood_score in P.ood_score: | |||||
| mean = 0 | |||||
| for ood in auroc_dict.keys(): | |||||
| mean += auroc_dict[ood][ood_score] | |||||
| mean_dict[ood_score] = mean / len(auroc_dict.keys()) | |||||
| auroc_dict['one_class_mean'] = mean_dict | |||||
| bests = [] | |||||
| for ood in auroc_dict.keys(): | |||||
| message = '' | |||||
| best_auroc = 0 | |||||
| for ood_score, auroc in auroc_dict[ood].items(): | |||||
| message += '[%s %s %.4f] ' % (ood, ood_score, auroc) | |||||
| if auroc > best_auroc: | |||||
| best_auroc = auroc | |||||
| message += '[%s %s %.4f] ' % (ood, 'best', best_auroc) | |||||
| if P.print_score: | |||||
| print(message) | |||||
| bests.append(best_auroc) | |||||
| bests = map('{:.4f}'.format, bests) | |||||
| print('\t'.join(bests)) | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| if __name__ == '__main__': | |||||
| main() |
+ 1
- 0
evals/__init__.py
View File
| from evals.evals import test_classifier, eval_ood_detection |
BIN
evals/__pycache__/__init__.cpython-36.pyc
View File
BIN
evals/__pycache__/__init__.cpython-37.pyc
View File
BIN
evals/__pycache__/evals.cpython-36.pyc
View File
BIN
evals/__pycache__/evals.cpython-37.pyc
View File
BIN
evals/__pycache__/ood_pre.cpython-36.pyc
View File
BIN
evals/__pycache__/ood_pre.cpython-37.pyc
View File
+ 201
- 0
evals/evals.py
View File
| import time | |||||
| import itertools | |||||
| import diffdist.functional as distops | |||||
| import numpy as np | |||||
| import torch | |||||
| import torch.distributed as dist | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| from sklearn.metrics import roc_auc_score | |||||
| import models.transform_layers as TL | |||||
| from utils.temperature_scaling import _ECELoss | |||||
| from utils.utils import AverageMeter, set_random_seed, normalize | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| ece_criterion = _ECELoss().to(device) | |||||
| def error_k(output, target, ks=(1,)): | |||||
| """Computes the precision@k for the specified values of k""" | |||||
| max_k = max(ks) | |||||
| batch_size = target.size(0) | |||||
| _, pred = output.topk(max_k, 1, True, True) | |||||
| pred = pred.t() | |||||
| correct = pred.eq(target.view(1, -1).expand_as(pred)) | |||||
| results = [] | |||||
| for k in ks: | |||||
| correct_k = correct[:k].view(-1).float().sum(0) | |||||
| results.append(100.0 - correct_k.mul_(100.0 / batch_size)) | |||||
| return results | |||||
| def test_classifier(P, model, loader, steps, marginal=False, logger=None): | |||||
| error_top1 = AverageMeter() | |||||
| error_calibration = AverageMeter() | |||||
| if logger is None: | |||||
| log_ = print | |||||
| else: | |||||
| log_ = logger.log | |||||
| # Switch to evaluate mode | |||||
| mode = model.training | |||||
| model.eval() | |||||
| for n, (images, labels) in enumerate(loader): | |||||
| batch_size = images.size(0) | |||||
| images, labels = images.to(device), labels.to(device) | |||||
| if marginal: | |||||
| outputs = 0 | |||||
| for i in range(4): | |||||
| rot_images = torch.rot90(images, i, (2, 3)) | |||||
| _, outputs_aux = model(rot_images, joint=True) | |||||
| outputs += outputs_aux['joint'][:, P.n_classes * i: P.n_classes * (i + 1)] / 4. | |||||
| else: | |||||
| outputs = model(images) | |||||
| top1, = error_k(outputs.data, labels, ks=(1,)) | |||||
| error_top1.update(top1.item(), batch_size) | |||||
| ece = ece_criterion(outputs, labels) * 100 | |||||
| error_calibration.update(ece.item(), batch_size) | |||||
| if n % 100 == 0: | |||||
| log_('[Test %3d] [Test@1 %.3f] [ECE %.3f]' % | |||||
| (n, error_top1.value, error_calibration.value)) | |||||
| log_(' * [Error@1 %.3f] [ECE %.3f]' % | |||||
| (error_top1.average, error_calibration.average)) | |||||
| if logger is not None: | |||||
| logger.scalar_summary('eval/clean_error', error_top1.average, steps) | |||||
| logger.scalar_summary('eval/ece', error_calibration.average, steps) | |||||
| model.train(mode) | |||||
| return error_top1.average | |||||
| def eval_ood_detection(P, model, id_loader, ood_loaders, ood_scores, train_loader=None, simclr_aug=None): | |||||
| auroc_dict = dict() | |||||
| for ood in ood_loaders.keys(): | |||||
| auroc_dict[ood] = dict() | |||||
| for ood_score in ood_scores: | |||||
| # compute scores for ID and OOD samples | |||||
| score_func = get_ood_score_func(P, model, ood_score, simclr_aug=simclr_aug) | |||||
| save_path = f'plot/score_in_{P.dataset}_{ood_score}' | |||||
| if P.one_class_idx is not None: | |||||
| save_path += f'_{P.one_class_idx}' | |||||
| scores_id = get_scores(id_loader, score_func) | |||||
| if P.save_score: | |||||
| np.save(f'{save_path}.npy', scores_id) | |||||
| for ood, ood_loader in ood_loaders.items(): | |||||
| if ood == 'interp': | |||||
| scores_ood = get_scores_interp(id_loader, score_func) | |||||
| auroc_dict['interp'][ood_score] = get_auroc(scores_id, scores_ood) | |||||
| else: | |||||
| scores_ood = get_scores(ood_loader, score_func) | |||||
| auroc_dict[ood][ood_score] = get_auroc(scores_id, scores_ood) | |||||
| if P.save_score: | |||||
| np.save(f'{save_path}_out_{ood}.npy', scores_ood) | |||||
| return auroc_dict | |||||
| def get_ood_score_func(P, model, ood_score, simclr_aug=None): | |||||
| def score_func(x): | |||||
| return compute_ood_score(P, model, ood_score, x, simclr_aug=simclr_aug) | |||||
| return score_func | |||||
| def get_scores(loader, score_func): | |||||
| scores = [] | |||||
| for i, (x, _) in enumerate(loader): | |||||
| s = score_func(x.to(device)) | |||||
| assert s.dim() == 1 and s.size(0) == x.size(0) | |||||
| scores.append(s.detach().cpu().numpy()) | |||||
| return np.concatenate(scores) | |||||
| def get_scores_interp(loader, score_func): | |||||
| scores = [] | |||||
| for i, (x, _) in enumerate(loader): | |||||
| x_interp = (x + last) / 2 if i > 0 else x # omit the first batch, assume batch sizes are equal | |||||
| last = x # save the last batch | |||||
| s = score_func(x_interp.to(device)) | |||||
| assert s.dim() == 1 and s.size(0) == x.size(0) | |||||
| scores.append(s.detach().cpu().numpy()) | |||||
| return np.concatenate(scores) | |||||
| def get_auroc(scores_id, scores_ood): | |||||
| scores = np.concatenate([scores_id, scores_ood]) | |||||
| labels = np.concatenate([np.ones_like(scores_id), np.zeros_like(scores_ood)]) | |||||
| return roc_auc_score(labels, scores) | |||||
| def compute_ood_score(P, model, ood_score, x, simclr_aug=None): | |||||
| model.eval() | |||||
| if ood_score == 'clean_norm': | |||||
| _, output_aux = model(x, penultimate=True, simclr=True) | |||||
| score = output_aux[P.ood_layer].norm(dim=1) | |||||
| return score | |||||
| elif ood_score == 'similar': | |||||
| assert simclr_aug is not None # require custom simclr augmentation | |||||
| sample_num = 2 # fast evaluation | |||||
| feats = get_features(model, simclr_aug, x, layer=P.ood_layer, sample_num=sample_num) | |||||
| feats_avg = sum(feats) / len(feats) | |||||
| scores = [] | |||||
| for seed in range(sample_num): | |||||
| sim = torch.cosine_similarity(feats[seed], feats_avg) | |||||
| scores.append(sim) | |||||
| return sum(scores) / len(scores) | |||||
| elif ood_score == 'baseline': | |||||
| outputs, outputs_aux = model(x, penultimate=True) | |||||
| scores = F.softmax(outputs, dim=1).max(dim=1)[0] | |||||
| return scores | |||||
| elif ood_score == 'baseline_marginalized': | |||||
| total_outputs = 0 | |||||
| for i in range(4): | |||||
| x_rot = torch.rot90(x, i, (2, 3)) | |||||
| outputs, outputs_aux = model(x_rot, penultimate=True, joint=True) | |||||
| total_outputs += outputs_aux['joint'][:, P.n_classes * i:P.n_classes * (i + 1)] | |||||
| scores = F.softmax(total_outputs / 4., dim=1).max(dim=1)[0] | |||||
| return scores | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| def get_features(model, simclr_aug, x, layer='simclr', sample_num=1): | |||||
| model.eval() | |||||
| feats = [] | |||||
| for seed in range(sample_num): | |||||
| set_random_seed(seed) | |||||
| x_t = simclr_aug(x) | |||||
| with torch.no_grad(): | |||||
| _, output_aux = model(x_t, penultimate=True, simclr=True, shift=True) | |||||
| feats.append(output_aux[layer]) | |||||
| return feats |
+ 242
- 0
evals/ood_pre.py
View File
| import os | |||||
| from copy import deepcopy | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| import numpy as np | |||||
| import models.transform_layers as TL | |||||
| from utils.utils import set_random_seed, normalize | |||||
| from evals.evals import get_auroc | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| hflip = TL.HorizontalFlipLayer().to(device) | |||||
| def eval_ood_detection(P, model, id_loader, ood_loaders, ood_scores, train_loader=None, simclr_aug=None): | |||||
| auroc_dict = dict() | |||||
| for ood in ood_loaders.keys(): | |||||
| auroc_dict[ood] = dict() | |||||
| assert len(ood_scores) == 1 # assume single ood_score for simplicity | |||||
| ood_score = ood_scores[0] | |||||
| base_path = os.path.split(P.load_path)[0] # checkpoint directory | |||||
| prefix = f'{P.ood_samples}' | |||||
| if P.resize_fix: | |||||
| prefix += f'_resize_fix_{P.resize_factor}' | |||||
| else: | |||||
| prefix += f'_resize_range_{P.resize_factor}' | |||||
| prefix = os.path.join(base_path, f'feats_{prefix}') | |||||
| kwargs = { | |||||
| 'simclr_aug': simclr_aug, | |||||
| 'sample_num': P.ood_samples, | |||||
| 'layers': P.ood_layer, | |||||
| } | |||||
| print('Pre-compute global statistics...') | |||||
| feats_train = get_features(P, f'{P.dataset}_train', model, train_loader, prefix=prefix, **kwargs) # (M, T, d) | |||||
| P.axis = [] | |||||
| for f in feats_train['simclr'].chunk(P.K_shift, dim=1): | |||||
| axis = f.mean(dim=1) # (M, d) | |||||
| P.axis.append(normalize(axis, dim=1).to(device)) | |||||
| print('axis size: ' + ' '.join(map(lambda x: str(len(x)), P.axis))) | |||||
| f_sim = [f.mean(dim=1) for f in feats_train['simclr'].chunk(P.K_shift, dim=1)] # list of (M, d) | |||||
| f_shi = [f.mean(dim=1) for f in feats_train['shift'].chunk(P.K_shift, dim=1)] # list of (M, 4) | |||||
| weight_sim = [] | |||||
| weight_shi = [] | |||||
| for shi in range(P.K_shift): | |||||
| sim_norm = f_sim[shi].norm(dim=1) # (M) | |||||
| shi_mean = f_shi[shi][:, shi] # (M) | |||||
| weight_sim.append(1 / sim_norm.mean().item()) | |||||
| weight_shi.append(1 / shi_mean.mean().item()) | |||||
| if ood_score == 'simclr': | |||||
| P.weight_sim = [1] | |||||
| P.weight_shi = [0] | |||||
| elif ood_score == 'CSI': | |||||
| P.weight_sim = weight_sim | |||||
| P.weight_shi = weight_shi | |||||
| else: | |||||
| raise ValueError() | |||||
| print(f'weight_sim:\t' + '\t'.join(map('{:.4f}'.format, P.weight_sim))) | |||||
| print(f'weight_shi:\t' + '\t'.join(map('{:.4f}'.format, P.weight_shi))) | |||||
| print('Pre-compute features...') | |||||
| feats_id = get_features(P, P.dataset, model, id_loader, prefix=prefix, **kwargs) # (N, T, d) | |||||
| feats_ood = dict() | |||||
| for ood, ood_loader in ood_loaders.items(): | |||||
| if ood == 'interp': | |||||
| feats_ood[ood] = get_features(P, ood, model, id_loader, interp=True, prefix=prefix, **kwargs) | |||||
| else: | |||||
| feats_ood[ood] = get_features(P, ood, model, ood_loader, prefix=prefix, **kwargs) | |||||
| print(f'Compute OOD scores... (score: {ood_score})') | |||||
| scores_id = get_scores(P, feats_id, ood_score).numpy() | |||||
| scores_ood = dict() | |||||
| if P.one_class_idx is not None: | |||||
| one_class_score = [] | |||||
| for ood, feats in feats_ood.items(): | |||||
| scores_ood[ood] = get_scores(P, feats, ood_score).numpy() | |||||
| auroc_dict[ood][ood_score] = get_auroc(scores_id, scores_ood[ood]) | |||||
| if P.one_class_idx is not None: | |||||
| one_class_score.append(scores_ood[ood]) | |||||
| if P.one_class_idx is not None: | |||||
| one_class_score = np.concatenate(one_class_score) | |||||
| one_class_total = get_auroc(scores_id, one_class_score) | |||||
| print(f'One_class_real_mean: {one_class_total}') | |||||
| if P.print_score: | |||||
| print_score(P.dataset, scores_id) | |||||
| for ood, scores in scores_ood.items(): | |||||
| print_score(ood, scores) | |||||
| return auroc_dict | |||||
| def get_scores(P, feats_dict, ood_score): | |||||
| # convert to gpu tensor | |||||
| feats_sim = feats_dict['simclr'].to(device) | |||||
| feats_shi = feats_dict['shift'].to(device) | |||||
| N = feats_sim.size(0) | |||||
| # compute scores | |||||
| scores = [] | |||||
| for f_sim, f_shi in zip(feats_sim, feats_shi): | |||||
| f_sim = [f.mean(dim=0, keepdim=True) for f in f_sim.chunk(P.K_shift)] # list of (1, d) | |||||
| f_shi = [f.mean(dim=0, keepdim=True) for f in f_shi.chunk(P.K_shift)] # list of (1, 4) | |||||
| score = 0 | |||||
| for shi in range(P.K_shift): | |||||
| score += (f_sim[shi] * P.axis[shi]).sum(dim=1).max().item() * P.weight_sim[shi] | |||||
| score += f_shi[shi][:, shi].item() * P.weight_shi[shi] | |||||
| score = score / P.K_shift | |||||
| scores.append(score) | |||||
| scores = torch.tensor(scores) | |||||
| assert scores.dim() == 1 and scores.size(0) == N # (N) | |||||
| return scores.cpu() | |||||
| def get_features(P, data_name, model, loader, interp=False, prefix='', | |||||
| simclr_aug=None, sample_num=1, layers=('simclr', 'shift')): | |||||
| if not isinstance(layers, (list, tuple)): | |||||
| layers = [layers] | |||||
| # load pre-computed features if exists | |||||
| feats_dict = dict() | |||||
| # for layer in layers: | |||||
| # path = prefix + f'_{data_name}_{layer}.pth' | |||||
| # if os.path.exists(path): | |||||
| # feats_dict[layer] = torch.load(path) | |||||
| # pre-compute features and save to the path | |||||
| left = [layer for layer in layers if layer not in feats_dict.keys()] | |||||
| if len(left) > 0: | |||||
| _feats_dict = _get_features(P, model, loader, interp, (P.dataset == 'imagenet' or | |||||
| P.dataset == 'CNMC' or | |||||
| P.dataset == 'CNMC_grayscale'), | |||||
| simclr_aug, sample_num, layers=left) | |||||
| for layer, feats in _feats_dict.items(): | |||||
| path = prefix + f'_{data_name}_{layer}.pth' | |||||
| torch.save(_feats_dict[layer], path) | |||||
| feats_dict[layer] = feats # update value | |||||
| return feats_dict | |||||
| def _get_features(P, model, loader, interp=False, imagenet=False, simclr_aug=None, | |||||
| sample_num=1, layers=('simclr', 'shift')): | |||||
| if not isinstance(layers, (list, tuple)): | |||||
| layers = [layers] | |||||
| # check if arguments are valid | |||||
| assert simclr_aug is not None | |||||
| if imagenet is True: # assume batch_size = 1 for ImageNet | |||||
| sample_num = 1 | |||||
| # compute features in full dataset | |||||
| model.eval() | |||||
| feats_all = {layer: [] for layer in layers} # initialize: empty list | |||||
| for i, (x, _) in enumerate(loader): | |||||
| if interp: | |||||
| x_interp = (x + last) / 2 if i > 0 else x # omit the first batch, assume batch sizes are equal | |||||
| last = x # save the last batch | |||||
| x = x_interp # use interp as current batch | |||||
| if imagenet is True: | |||||
| x = torch.cat(x[0], dim=0) # augmented list of x | |||||
| x = x.to(device) # gpu tensor | |||||
| # compute features in one batch | |||||
| feats_batch = {layer: [] for layer in layers} # initialize: empty list | |||||
| for seed in range(sample_num): | |||||
| set_random_seed(seed) | |||||
| if P.K_shift > 1: | |||||
| x_t = torch.cat([P.shift_trans(hflip(x), k) for k in range(P.K_shift)]) | |||||
| else: | |||||
| x_t = x # No shifting: SimCLR | |||||
| x_t = simclr_aug(x_t) | |||||
| # compute augmented features | |||||
| with torch.no_grad(): | |||||
| kwargs = {layer: True for layer in layers} # only forward selected layers | |||||
| _, output_aux = model(x_t, **kwargs) | |||||
| # add features in one batch | |||||
| for layer in layers: | |||||
| feats = output_aux[layer].cpu() | |||||
| if imagenet is False: | |||||
| feats_batch[layer] += feats.chunk(P.K_shift) | |||||
| else: | |||||
| feats_batch[layer] += [feats] # (B, d) cpu tensor | |||||
| # concatenate features in one batch | |||||
| for key, val in feats_batch.items(): | |||||
| if imagenet: | |||||
| feats_batch[key] = torch.stack(val, dim=0) # (B, T, d) | |||||
| else: | |||||
| feats_batch[key] = torch.stack(val, dim=1) # (B, T, d) | |||||
| # add features in full dataset | |||||
| for layer in layers: | |||||
| feats_all[layer] += [feats_batch[layer]] | |||||
| # concatenate features in full dataset | |||||
| for key, val in feats_all.items(): | |||||
| feats_all[key] = torch.cat(val, dim=0) # (N, T, d) | |||||
| # reshape order | |||||
| if imagenet is False: | |||||
| # Convert [1,2,3,4, 1,2,3,4] -> [1,1, 2,2, 3,3, 4,4] | |||||
| for key, val in feats_all.items(): | |||||
| N, T, d = val.size() # T = K * T' | |||||
| val = val.view(N, -1, P.K_shift, d) # (N, T', K, d) | |||||
| val = val.transpose(2, 1) # (N, 4, T', d) | |||||
| val = val.reshape(N, T, d) # (N, T, d) | |||||
| feats_all[key] = val | |||||
| return feats_all | |||||
| def print_score(data_name, scores): | |||||
| quantile = np.quantile(scores, np.arange(0, 1.1, 0.1)) | |||||
| print('{:18s} '.format(data_name) + | |||||
| '{:.4f} +- {:.4f} '.format(np.mean(scores), np.std(scores)) + | |||||
| ' '.join(['q{:d}: {:.4f}'.format(i * 10, quantile[i]) for i in range(11)])) | |||||
BIN
figures/CSI_teaser.png
View File
{kind=link}
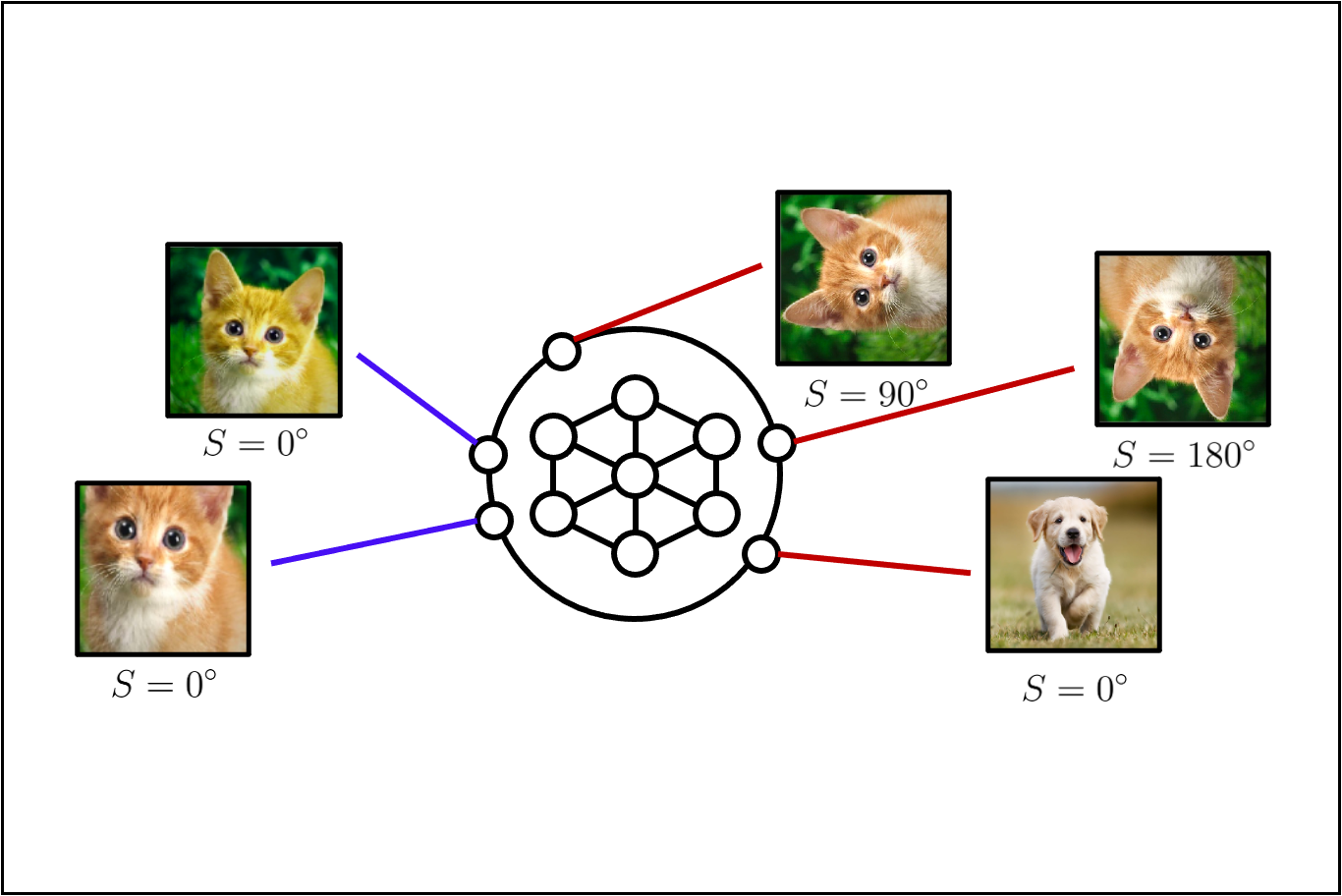
BIN
figures/fixed_ood_benchmarks.png
View File
{kind=link}

BIN
figures/shifting_transformations.png
View File
{kind=link}
+ 37
- 0
main.py
View File
| from sys import argv | |||||
| from os import system | |||||
| from datasets.prepare_data import prep, resize | |||||
| import torch | |||||
| import os | |||||
| from datasets.postprocess_data import postprocess_data | |||||
| DATA_BASE_DIR = r'/home/feoktistovar67431/CSI/CSI_local/main.py' | |||||
| BASE_DIR = '/home/feoktistovar67431/CSI/CSI_local/' | |||||
| def main(): | |||||
| for argument in argv: | |||||
| if argument == '--proc_step': | |||||
| proc_step = argv[argv.index(argument)+1] | |||||
| if proc_step == 'eval': | |||||
| system("eval.py "+' '.join(argv[1:])) | |||||
| if proc_step == 'train': | |||||
| system(BASE_DIR + os.sep + "eval.py " + ' '.join(argv[1:])) | |||||
| if proc_step == 'plot': | |||||
| plot_data() | |||||
| elif proc_step == 'post_proc': | |||||
| postprocess_data( | |||||
| [ | |||||
| r'\CNMC_resnet18_unsup_simclr_CSI_shift_cutperm4_one_class_0\log.txt', | |||||
| r'\CNMC_resnet18_unsup_simclr_CSI_shift_cutperm4_one_class_0_64px\log.txt', | |||||
| r'\CNMC_resnet18_unsup_simclr_CSI_shift_cutperm16_one_class_0_32px\log.txt', | |||||
| r'\CNMC_resnet18_unsup_simclr_CSI_shift_cutperm_one_class_0_64px_batch64\log.txt', | |||||
| r'\CNMC_resnet18_unsup_simclr_CSI_shift_rotation_one_class_0\log.txt', | |||||
| r"\CNMC_resnet18_unsup_simclr_CSI_shift_gauss_one_class_0_32px\log.txt" | |||||
| # r'\cifar10_resnet18_unsup_simclr_CSI_shift_rotation_one_class_1\log.txt' | |||||
| ] | |||||
| ) | |||||
| if __name__ == '__main__': | |||||
| main() |
+ 0
- 0
models/__init__.py
View File
BIN
models/__pycache__/__init__.cpython-36.pyc
View File
BIN
models/__pycache__/__init__.cpython-37.pyc
View File
BIN
models/__pycache__/base_model.cpython-36.pyc
View File
BIN
models/__pycache__/base_model.cpython-37.pyc
View File
BIN
models/__pycache__/classifier.cpython-36.pyc
View File
BIN
models/__pycache__/classifier.cpython-37.pyc
View File
BIN
models/__pycache__/resnet.cpython-36.pyc
View File
BIN
models/__pycache__/resnet.cpython-37.pyc
View File
BIN
models/__pycache__/resnet_imagenet.cpython-36.pyc
View File
BIN
models/__pycache__/resnet_imagenet.cpython-37.pyc
View File
BIN
models/__pycache__/transform_layers.cpython-36.pyc
View File
BIN
models/__pycache__/transform_layers.cpython-37.pyc
View File
+ 48
- 0
models/base_model.py
View File
| from abc import * | |||||
| import torch.nn as nn | |||||
| class BaseModel(nn.Module, metaclass=ABCMeta): | |||||
| def __init__(self, last_dim, num_classes=10, simclr_dim=128): | |||||
| super(BaseModel, self).__init__() | |||||
| self.linear = nn.Linear(last_dim, num_classes) | |||||
| self.simclr_layer = nn.Sequential( | |||||
| nn.Linear(last_dim, last_dim), | |||||
| nn.ReLU(), | |||||
| nn.Linear(last_dim, simclr_dim), | |||||
| ) | |||||
| self.shift_cls_layer = nn.Linear(last_dim, 2) | |||||
| self.joint_distribution_layer = nn.Linear(last_dim, 4 * num_classes) | |||||
| @abstractmethod | |||||
| def penultimate(self, inputs, all_features=False): | |||||
| pass | |||||
| def forward(self, inputs, penultimate=False, simclr=False, shift=False, joint=False): | |||||
| _aux = {} | |||||
| _return_aux = False | |||||
| features = self.penultimate(inputs) | |||||
| output = self.linear(features) | |||||
| if penultimate: | |||||
| _return_aux = True | |||||
| _aux['penultimate'] = features | |||||
| if simclr: | |||||
| _return_aux = True | |||||
| _aux['simclr'] = self.simclr_layer(features) | |||||
| if shift: | |||||
| _return_aux = True | |||||
| _aux['shift'] = self.shift_cls_layer(features) | |||||
| if joint: | |||||
| _return_aux = True | |||||
| _aux['joint'] = self.joint_distribution_layer(features) | |||||
| if _return_aux: | |||||
| return output, _aux | |||||
| return output |
+ 135
- 0
models/classifier.py
View File
| import torch.nn as nn | |||||
| from models.resnet import ResNet18, ResNet34, ResNet50 | |||||
| from models.resnet_imagenet import resnet18, resnet50 | |||||
| import models.transform_layers as TL | |||||
| from torchvision import transforms | |||||
| def get_simclr_augmentation(P, image_size): | |||||
| """ | |||||
| Creates positive data for training. | |||||
| :param P: parsed arguments | |||||
| :param image_size: size of image | |||||
| :return: transformation | |||||
| """ | |||||
| # parameter for resizecrop | |||||
| resize_scale = (P.resize_factor, 1.0) # resize scaling factor | |||||
| if P.resize_fix: # if resize_fix is True, use same scale | |||||
| resize_scale = (P.resize_factor, P.resize_factor) | |||||
| # Align augmentation | |||||
| s = P.color_distort | |||||
| color_jitter = TL.ColorJitterLayer(brightness=s*0.8, contrast=s*0.8, saturation=s*0.8, hue=s*0.2, p=0.8) | |||||
| color_gray = TL.RandomColorGrayLayer(p=0.2) | |||||
| resize_crop = TL.RandomResizedCropLayer(scale=resize_scale, size=(image_size[0], image_size[1])) | |||||
| #v_flip = transforms.RandomVerticalFlip() | |||||
| #h_flip = transforms.RandomHorizontalFlip() | |||||
| rand_aff = transforms.RandomAffine(degrees=360, translate=(0.2, 0.2)) | |||||
| # Transform define # | |||||
| if P.dataset == 'imagenet': # Using RandomResizedCrop at PIL transform | |||||
| transform = nn.Sequential( | |||||
| color_jitter, | |||||
| color_gray, | |||||
| ) | |||||
| elif P.dataset == 'CNMC': | |||||
| transform = nn.Sequential( | |||||
| color_jitter, | |||||
| color_gray, | |||||
| resize_crop, | |||||
| ) | |||||
| else: | |||||
| transform = nn.Sequential( | |||||
| color_jitter, | |||||
| color_gray, | |||||
| resize_crop, | |||||
| ) | |||||
| return transform | |||||
| def get_shift_module(P, eval=False): | |||||
| """ | |||||
| Creates shift transformation (negative). | |||||
| :param P: parsed arguments | |||||
| :param eval: whether it is an evaluation step or not | |||||
| :return: transformation | |||||
| """ | |||||
| if P.shift_trans_type == 'rotation': | |||||
| shift_transform = TL.Rotation() | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'cutperm': | |||||
| shift_transform = TL.CutPerm() | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'noise': | |||||
| shift_transform = TL.GaussNoise(mean=P.noise_mean, std=P.noise_std) | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'randpers': | |||||
| shift_transform = TL.RandPers(distortion_scale=P.distortion_scale, p=1) | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'sharp': | |||||
| shift_transform = TL.RandomAdjustSharpness(sharpness_factor=P.sharpness_factor, p=1) | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'blur': | |||||
| kernel_size = int(int(P.res.replace('px', ''))*0.1) | |||||
| if kernel_size%2 == 0: | |||||
| kernel_size+=1 | |||||
| sigma = (0.1, float(P.blur_sigma)) | |||||
| shift_transform = TL.GaussBlur(kernel_size=kernel_size, sigma=sigma) | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'blur_randpers': | |||||
| kernel_size = int(P.res.replace('px', '')) * 0.1 | |||||
| sigma = (0.1, float(P.blur_sigma)) | |||||
| shift_transform = TL.BlurRandpers(kernel_size=kernel_size, sigma=sigma, distortion_scale=P.distortion_scale, p=1) | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'blur_sharp': | |||||
| kernel_size = int(P.res.replace('px', '')) * 0.1 | |||||
| sigma = (0.1, float(P.blur_sigma)) | |||||
| shift_transform = TL.BlurSharpness(kernel_size=kernel_size, sigma=sigma, sharpness_factor=P.sharpness_factor, p=1) | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'randpers_sharp': | |||||
| shift_transform = TL.RandpersSharpness(distortion_scale=P.distortion_scale, p=1, sharpness_factor=P.sharpness_factor) | |||||
| K_shift = 4 | |||||
| elif P.shift_trans_type == 'blur_randpers_sharp': | |||||
| kernel_size = int(P.res.replace('px', '')) * 0.1 | |||||
| sigma = (0.1, float(P.blur_sigma)) | |||||
| shift_transform = TL.BlurRandpersSharpness(kernel_size=kernel_size, sigma=sigma, distortion_scale=P.distortion_scale, p=1, sharpness_factor=P.sharpness_factor) | |||||
| K_shift = 4 | |||||
| else: | |||||
| shift_transform = nn.Identity() | |||||
| K_shift = 1 | |||||
| if not eval and not ('sup' in P.mode): | |||||
| assert P.batch_size == int(128/K_shift) | |||||
| return shift_transform, K_shift | |||||
| def get_shift_classifer(model, K_shift): | |||||
| model.shift_cls_layer = nn.Linear(model.last_dim, K_shift) | |||||
| return model | |||||
| def get_classifier(mode, n_classes=10): | |||||
| if mode == 'resnet18': | |||||
| classifier = ResNet18(num_classes=n_classes) | |||||
| elif mode == 'resnet34': | |||||
| classifier = ResNet34(num_classes=n_classes) | |||||
| elif mode == 'resnet50': | |||||
| classifier = ResNet50(num_classes=n_classes) | |||||
| elif mode == 'resnet18_imagenet': | |||||
| classifier = resnet18(num_classes=n_classes) | |||||
| elif mode == 'resnet50_imagenet': | |||||
| classifier = resnet50(num_classes=n_classes) | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| return classifier | |||||
+ 189
- 0
models/resnet.py
View File
| '''ResNet in PyTorch. | |||||
| BasicBlock and Bottleneck module is from the original ResNet paper: | |||||
| [1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun | |||||
| Deep Residual Learning for Image Recognition. arXiv:1512.03385 | |||||
| PreActBlock and PreActBottleneck module is from the later paper: | |||||
| [2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun | |||||
| Identity Mappings in Deep Residual Networks. arXiv:1603.05027 | |||||
| ''' | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| from models.base_model import BaseModel | |||||
| from models.transform_layers import NormalizeLayer | |||||
| from torch.nn.utils import spectral_norm | |||||
| def conv3x3(in_planes, out_planes, stride=1): | |||||
| return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False) | |||||
| class BasicBlock(nn.Module): | |||||
| expansion = 1 | |||||
| def __init__(self, in_planes, planes, stride=1): | |||||
| super(BasicBlock, self).__init__() | |||||
| self.conv1 = conv3x3(in_planes, planes, stride) | |||||
| self.conv2 = conv3x3(planes, planes) | |||||
| self.bn1 = nn.BatchNorm2d(planes) | |||||
| self.bn2 = nn.BatchNorm2d(planes) | |||||
| self.shortcut = nn.Sequential() | |||||
| if stride != 1 or in_planes != self.expansion*planes: | |||||
| self.shortcut = nn.Sequential( | |||||
| nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False), | |||||
| nn.BatchNorm2d(self.expansion*planes) | |||||
| ) | |||||
| def forward(self, x): | |||||
| out = F.relu(self.bn1(self.conv1(x))) | |||||
| out = self.bn2(self.conv2(out)) | |||||
| out += self.shortcut(x) | |||||
| out = F.relu(out) | |||||
| return out | |||||
| class PreActBlock(nn.Module): | |||||
| '''Pre-activation version of the BasicBlock.''' | |||||
| expansion = 1 | |||||
| def __init__(self, in_planes, planes, stride=1): | |||||
| super(PreActBlock, self).__init__() | |||||
| self.conv1 = conv3x3(in_planes, planes, stride) | |||||
| self.conv2 = conv3x3(planes, planes) | |||||
| self.bn1 = nn.BatchNorm2d(in_planes) | |||||
| self.bn2 = nn.BatchNorm2d(planes) | |||||
| self.shortcut = nn.Sequential() | |||||
| if stride != 1 or in_planes != self.expansion*planes: | |||||
| self.shortcut = nn.Sequential( | |||||
| nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False) | |||||
| ) | |||||
| def forward(self, x): | |||||
| out = F.relu(self.bn1(x)) | |||||
| shortcut = self.shortcut(out) | |||||
| out = self.conv1(out) | |||||
| out = self.conv2(F.relu(self.bn2(out))) | |||||
| out += shortcut | |||||
| return out | |||||
| class Bottleneck(nn.Module): | |||||
| expansion = 4 | |||||
| def __init__(self, in_planes, planes, stride=1): | |||||
| super(Bottleneck, self).__init__() | |||||
| self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) | |||||
| self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) | |||||
| self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False) | |||||
| self.bn1 = nn.BatchNorm2d(planes) | |||||
| self.bn2 = nn.BatchNorm2d(planes) | |||||
| self.bn3 = nn.BatchNorm2d(self.expansion * planes) | |||||
| self.shortcut = nn.Sequential() | |||||
| if stride != 1 or in_planes != self.expansion*planes: | |||||
| self.shortcut = nn.Sequential( | |||||
| nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False), | |||||
| nn.BatchNorm2d(self.expansion*planes) | |||||
| ) | |||||
| def forward(self, x): | |||||
| out = F.relu(self.bn1(self.conv1(x))) | |||||
| out = F.relu(self.bn2(self.conv2(out))) | |||||
| out = self.bn3(self.conv3(out)) | |||||
| out += self.shortcut(x) | |||||
| out = F.relu(out) | |||||
| return out | |||||
| class PreActBottleneck(nn.Module): | |||||
| '''Pre-activation version of the original Bottleneck module.''' | |||||
| expansion = 4 | |||||
| def __init__(self, in_planes, planes, stride=1): | |||||
| super(PreActBottleneck, self).__init__() | |||||
| self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) | |||||
| self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) | |||||
| self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False) | |||||
| self.bn1 = nn.BatchNorm2d(in_planes) | |||||
| self.bn2 = nn.BatchNorm2d(planes) | |||||
| self.bn3 = nn.BatchNorm2d(planes) | |||||
| self.shortcut = nn.Sequential() | |||||
| if stride != 1 or in_planes != self.expansion*planes: | |||||
| self.shortcut = nn.Sequential( | |||||
| nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False) | |||||
| ) | |||||
| def forward(self, x): | |||||
| out = F.relu(self.bn1(x)) | |||||
| shortcut = self.shortcut(out) | |||||
| out = self.conv1(out) | |||||
| out = self.conv2(F.relu(self.bn2(out))) | |||||
| out = self.conv3(F.relu(self.bn3(out))) | |||||
| out += shortcut | |||||
| return out | |||||
| class ResNet(BaseModel): | |||||
| def __init__(self, block, num_blocks, num_classes=10): | |||||
| last_dim = 512 * block.expansion | |||||
| super(ResNet, self).__init__(last_dim, num_classes) | |||||
| self.in_planes = 64 | |||||
| self.last_dim = last_dim | |||||
| self.normalize = NormalizeLayer() | |||||
| self.conv1 = conv3x3(3, 64) | |||||
| self.bn1 = nn.BatchNorm2d(64) | |||||
| self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) | |||||
| self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) | |||||
| self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) | |||||
| self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) | |||||
| def _make_layer(self, block, planes, num_blocks, stride): | |||||
| strides = [stride] + [1]*(num_blocks-1) | |||||
| layers = [] | |||||
| for stride in strides: | |||||
| layers.append(block(self.in_planes, planes, stride)) | |||||
| self.in_planes = planes * block.expansion | |||||
| return nn.Sequential(*layers) | |||||
| def penultimate(self, x, all_features=False): | |||||
| out_list = [] | |||||
| out = self.normalize(x) | |||||
| out = self.conv1(out) | |||||
| out = self.bn1(out) | |||||
| out = F.relu(out) | |||||
| out_list.append(out) | |||||
| out = self.layer1(out) | |||||
| out_list.append(out) | |||||
| out = self.layer2(out) | |||||
| out_list.append(out) | |||||
| out = self.layer3(out) | |||||
| out_list.append(out) | |||||
| out = self.layer4(out) | |||||
| out_list.append(out) | |||||
| out = F.avg_pool2d(out, 4) | |||||
| out = out.view(out.size(0), -1) | |||||
| if all_features: | |||||
| return out, out_list | |||||
| else: | |||||
| return out | |||||
| def ResNet18(num_classes): | |||||
| return ResNet(BasicBlock, [2,2,2,2], num_classes=num_classes) | |||||
| def ResNet34(num_classes): | |||||
| return ResNet(BasicBlock, [3,4,6,3], num_classes=num_classes) | |||||
| def ResNet50(num_classes): | |||||
| return ResNet(Bottleneck, [3,4,6,3], num_classes=num_classes) |
+ 231
- 0
models/resnet_imagenet.py
View File
| import torch | |||||
| import torch.nn as nn | |||||
| from models.base_model import BaseModel | |||||
| from models.transform_layers import NormalizeLayer | |||||
| def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1): | |||||
| """3x3 convolution with padding""" | |||||
| return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, | |||||
| padding=dilation, groups=groups, bias=False, dilation=dilation) | |||||
| def conv1x1(in_planes, out_planes, stride=1): | |||||
| """1x1 convolution""" | |||||
| return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False) | |||||
| class BasicBlock(nn.Module): | |||||
| expansion = 1 | |||||
| def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, | |||||
| base_width=64, dilation=1, norm_layer=None): | |||||
| super(BasicBlock, self).__init__() | |||||
| if norm_layer is None: | |||||
| norm_layer = nn.BatchNorm2d | |||||
| if groups != 1 or base_width != 64: | |||||
| raise ValueError('BasicBlock only supports groups=1 and base_width=64') | |||||
| if dilation > 1: | |||||
| raise NotImplementedError("Dilation > 1 not supported in BasicBlock") | |||||
| # Both self.conv1 and self.downsample layers downsample the input when stride != 1 | |||||
| self.conv1 = conv3x3(inplanes, planes, stride) | |||||
| self.bn1 = norm_layer(planes) | |||||
| self.relu = nn.ReLU(inplace=True) | |||||
| self.conv2 = conv3x3(planes, planes) | |||||
| self.bn2 = norm_layer(planes) | |||||
| self.downsample = downsample | |||||
| self.stride = stride | |||||
| def forward(self, x): | |||||
| identity = x | |||||
| out = self.conv1(x) | |||||
| out = self.bn1(out) | |||||
| out = self.relu(out) | |||||
| out = self.conv2(out) | |||||
| out = self.bn2(out) | |||||
| if self.downsample is not None: | |||||
| identity = self.downsample(x) | |||||
| out += identity | |||||
| out = self.relu(out) | |||||
| return out | |||||
| class Bottleneck(nn.Module): | |||||
| # Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2) | |||||
| # while original implementation places the stride at the first 1x1 convolution(self.conv1) | |||||
| # according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385. | |||||
| # This variant is also known as ResNet V1.5 and improves accuracy according to | |||||
| # https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch. | |||||
| expansion = 4 | |||||
| def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, | |||||
| base_width=64, dilation=1, norm_layer=None): | |||||
| super(Bottleneck, self).__init__() | |||||
| if norm_layer is None: | |||||
| norm_layer = nn.BatchNorm2d | |||||
| width = int(planes * (base_width / 64.)) * groups | |||||
| # Both self.conv2 and self.downsample layers downsample the input when stride != 1 | |||||
| self.conv1 = conv1x1(inplanes, width) | |||||
| self.bn1 = norm_layer(width) | |||||
| self.conv2 = conv3x3(width, width, stride, groups, dilation) | |||||
| self.bn2 = norm_layer(width) | |||||
| self.conv3 = conv1x1(width, planes * self.expansion) | |||||
| self.bn3 = norm_layer(planes * self.expansion) | |||||
| self.relu = nn.ReLU(inplace=True) | |||||
| self.downsample = downsample | |||||
| self.stride = stride | |||||
| def forward(self, x): | |||||
| identity = x | |||||
| out = self.conv1(x) | |||||
| out = self.bn1(out) | |||||
| out = self.relu(out) | |||||
| out = self.conv2(out) | |||||
| out = self.bn2(out) | |||||
| out = self.relu(out) | |||||
| out = self.conv3(out) | |||||
| out = self.bn3(out) | |||||
| if self.downsample is not None: | |||||
| identity = self.downsample(x) | |||||
| out += identity | |||||
| out = self.relu(out) | |||||
| return out | |||||
| class ResNet(BaseModel): | |||||
| def __init__(self, block, layers, num_classes=10, | |||||
| zero_init_residual=False, groups=1, width_per_group=64, replace_stride_with_dilation=None, | |||||
| norm_layer=None): | |||||
| last_dim = 512 * block.expansion | |||||
| super(ResNet, self).__init__(last_dim, num_classes) | |||||
| if norm_layer is None: | |||||
| norm_layer = nn.BatchNorm2d | |||||
| self._norm_layer = norm_layer | |||||
| self.inplanes = 64 | |||||
| self.dilation = 1 | |||||
| if replace_stride_with_dilation is None: | |||||
| # each element in the tuple indicates if we should replace | |||||
| # the 2x2 stride with a dilated convolution instead | |||||
| replace_stride_with_dilation = [False, False, False] | |||||
| if len(replace_stride_with_dilation) != 3: | |||||
| raise ValueError("replace_stride_with_dilation should be None " | |||||
| "or a 3-element tuple, got {}".format(replace_stride_with_dilation)) | |||||
| self.groups = groups | |||||
| self.base_width = width_per_group | |||||
| self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, | |||||
| bias=False) | |||||
| self.bn1 = norm_layer(self.inplanes) | |||||
| self.relu = nn.ReLU(inplace=True) | |||||
| self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) | |||||
| self.layer1 = self._make_layer(block, 64, layers[0]) | |||||
| self.layer2 = self._make_layer(block, 128, layers[1], stride=2, | |||||
| dilate=replace_stride_with_dilation[0]) | |||||
| self.layer3 = self._make_layer(block, 256, layers[2], stride=2, | |||||
| dilate=replace_stride_with_dilation[1]) | |||||
| self.layer4 = self._make_layer(block, 512, layers[3], stride=2, | |||||
| dilate=replace_stride_with_dilation[2]) | |||||
| self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) | |||||
| self.normalize = NormalizeLayer() | |||||
| self.last_dim = 512 * block.expansion | |||||
| for m in self.modules(): | |||||
| if isinstance(m, nn.Conv2d): | |||||
| nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') | |||||
| elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)): | |||||
| nn.init.constant_(m.weight, 1) | |||||
| nn.init.constant_(m.bias, 0) | |||||
| # Zero-initialize the last BN in each residual branch, | |||||
| # so that the residual branch starts with zeros, and each residual block behaves like an identity. | |||||
| # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677 | |||||
| if zero_init_residual: | |||||
| for m in self.modules(): | |||||
| if isinstance(m, Bottleneck): | |||||
| nn.init.constant_(m.bn3.weight, 0) | |||||
| elif isinstance(m, BasicBlock): | |||||
| nn.init.constant_(m.bn2.weight, 0) | |||||
| def _make_layer(self, block, planes, blocks, stride=1, dilate=False): | |||||
| norm_layer = self._norm_layer | |||||
| downsample = None | |||||
| previous_dilation = self.dilation | |||||
| if dilate: | |||||
| self.dilation *= stride | |||||
| stride = 1 | |||||
| if stride != 1 or self.inplanes != planes * block.expansion: | |||||
| downsample = nn.Sequential( | |||||
| conv1x1(self.inplanes, planes * block.expansion, stride), | |||||
| norm_layer(planes * block.expansion), | |||||
| ) | |||||
| layers = [] | |||||
| layers.append(block(self.inplanes, planes, stride, downsample, self.groups, | |||||
| self.base_width, previous_dilation, norm_layer)) | |||||
| self.inplanes = planes * block.expansion | |||||
| for _ in range(1, blocks): | |||||
| layers.append(block(self.inplanes, planes, groups=self.groups, | |||||
| base_width=self.base_width, dilation=self.dilation, | |||||
| norm_layer=norm_layer)) | |||||
| return nn.Sequential(*layers) | |||||
| def penultimate(self, x, all_features=False): | |||||
| # See note [TorchScript super()] | |||||
| out_list = [] | |||||
| x = self.normalize(x) | |||||
| x = self.conv1(x) | |||||
| x = self.bn1(x) | |||||
| x = self.relu(x) | |||||
| x = self.maxpool(x) | |||||
| out_list.append(x) | |||||
| x = self.layer1(x) | |||||
| out_list.append(x) | |||||
| x = self.layer2(x) | |||||
| out_list.append(x) | |||||
| x = self.layer3(x) | |||||
| out_list.append(x) | |||||
| x = self.layer4(x) | |||||
| out_list.append(x) | |||||
| x = self.avgpool(x) | |||||
| x = torch.flatten(x, 1) | |||||
| if all_features: | |||||
| return x, out_list | |||||
| else: | |||||
| return x | |||||
| def _resnet(arch, block, layers, **kwargs): | |||||
| model = ResNet(block, layers, **kwargs) | |||||
| return model | |||||
| def resnet18(**kwargs): | |||||
| r"""ResNet-18 model from | |||||
| `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_ | |||||
| """ | |||||
| return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], **kwargs) | |||||
| def resnet50(**kwargs): | |||||
| r"""ResNet-50 model from | |||||
| `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_ | |||||
| """ | |||||
| return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], **kwargs) |
+ 643
- 0
models/transform_layers.py
View File
| import math | |||||
| import numbers | |||||
| import numpy as np | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| from torch.autograd import Function | |||||
| from torchvision import transforms | |||||
| if torch.__version__ >= '1.4.0': | |||||
| kwargs = {'align_corners': False} | |||||
| else: | |||||
| kwargs = {} | |||||
| def rgb2hsv(rgb): | |||||
| """Convert a 4-d RGB tensor to the HSV counterpart. | |||||
| Here, we compute hue using atan2() based on the definition in [1], | |||||
| instead of using the common lookup table approach as in [2, 3]. | |||||
| Those values agree when the angle is a multiple of 30°, | |||||
| otherwise they may differ at most ~1.2°. | |||||
| References | |||||
| [1] https://en.wikipedia.org/wiki/Hue | |||||
| [2] https://www.rapidtables.com/convert/color/rgb-to-hsv.html | |||||
| [3] https://github.com/scikit-image/scikit-image/blob/master/skimage/color/colorconv.py#L212 | |||||
| """ | |||||
| r, g, b = rgb[:, 0, :, :], rgb[:, 1, :, :], rgb[:, 2, :, :] | |||||
| Cmax = rgb.max(1)[0] | |||||
| Cmin = rgb.min(1)[0] | |||||
| delta = Cmax - Cmin | |||||
| hue = torch.atan2(math.sqrt(3) * (g - b), 2 * r - g - b) | |||||
| hue = (hue % (2 * math.pi)) / (2 * math.pi) | |||||
| saturate = delta / Cmax | |||||
| value = Cmax | |||||
| hsv = torch.stack([hue, saturate, value], dim=1) | |||||
| hsv[~torch.isfinite(hsv)] = 0. | |||||
| return hsv | |||||
| def hsv2rgb(hsv): | |||||
| """Convert a 4-d HSV tensor to the RGB counterpart. | |||||
| >>> %timeit hsv2rgb(hsv) | |||||
| 2.37 ms ± 13.4 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) | |||||
| >>> %timeit rgb2hsv_fast(rgb) | |||||
| 298 µs ± 542 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each) | |||||
| >>> torch.allclose(hsv2rgb(hsv), hsv2rgb_fast(hsv), atol=1e-6) | |||||
| True | |||||
| References | |||||
| [1] https://en.wikipedia.org/wiki/HSL_and_HSV#HSV_to_RGB_alternative | |||||
| """ | |||||
| h, s, v = hsv[:, [0]], hsv[:, [1]], hsv[:, [2]] | |||||
| c = v * s | |||||
| n = hsv.new_tensor([5, 3, 1]).view(3, 1, 1) | |||||
| k = (n + h * 6) % 6 | |||||
| t = torch.min(k, 4 - k) | |||||
| t = torch.clamp(t, 0, 1) | |||||
| return v - c * t | |||||
| class RandomResizedCropLayer(nn.Module): | |||||
| def __init__(self, size=None, scale=(0.08, 1.0), ratio=(3. / 4., 4. / 3.)): | |||||
| ''' | |||||
| Inception Crop | |||||
| size (tuple): size of fowarding image (C, W, H) | |||||
| scale (tuple): range of size of the origin size cropped | |||||
| ratio (tuple): range of aspect ratio of the origin aspect ratio cropped | |||||
| ''' | |||||
| super(RandomResizedCropLayer, self).__init__() | |||||
| _eye = torch.eye(2, 3) | |||||
| self.size = size | |||||
| self.register_buffer('_eye', _eye) | |||||
| self.scale = scale | |||||
| self.ratio = ratio | |||||
| def forward(self, inputs, whbias=None): | |||||
| _device = inputs.device | |||||
| N = inputs.size(0) | |||||
| _theta = self._eye.repeat(N, 1, 1) | |||||
| if whbias is None: | |||||
| whbias = self._sample_latent(inputs) | |||||
| _theta[:, 0, 0] = whbias[:, 0] | |||||
| _theta[:, 1, 1] = whbias[:, 1] | |||||
| _theta[:, 0, 2] = whbias[:, 2] | |||||
| _theta[:, 1, 2] = whbias[:, 3] | |||||
| grid = F.affine_grid(_theta, inputs.size(), **kwargs).to(_device) | |||||
| output = F.grid_sample(inputs, grid, padding_mode='reflection', **kwargs) | |||||
| if self.size is not None: | |||||
| output = F.adaptive_avg_pool2d(output, self.size) | |||||
| # output = F.adaptive_avg_pool2d(output, self.size) | |||||
| # output = F.adaptive_avg_pool2d(output, (self.size[0], self.size[1])) | |||||
| return output | |||||
| def _clamp(self, whbias): | |||||
| w = whbias[:, 0] | |||||
| h = whbias[:, 1] | |||||
| w_bias = whbias[:, 2] | |||||
| h_bias = whbias[:, 3] | |||||
| # Clamp with scale | |||||
| w = torch.clamp(w, *self.scale) | |||||
| h = torch.clamp(h, *self.scale) | |||||
| # Clamp with ratio | |||||
| w = self.ratio[0] * h + torch.relu(w - self.ratio[0] * h) | |||||
| w = self.ratio[1] * h - torch.relu(self.ratio[1] * h - w) | |||||
| # Clamp with bias range: w_bias \in (w - 1, 1 - w), h_bias \in (h - 1, 1 - h) | |||||
| w_bias = w - 1 + torch.relu(w_bias - w + 1) | |||||
| w_bias = 1 - w - torch.relu(1 - w - w_bias) | |||||
| h_bias = h - 1 + torch.relu(h_bias - h + 1) | |||||
| h_bias = 1 - h - torch.relu(1 - h - h_bias) | |||||
| whbias = torch.stack([w, h, w_bias, h_bias], dim=0).t() | |||||
| return whbias | |||||
| def _sample_latent(self, inputs): | |||||
| _device = inputs.device | |||||
| N, _, width, height = inputs.shape | |||||
| # N * 10 trial | |||||
| area = width * height | |||||
| target_area = np.random.uniform(*self.scale, N * 10) * area | |||||
| log_ratio = (math.log(self.ratio[0]), math.log(self.ratio[1])) | |||||
| aspect_ratio = np.exp(np.random.uniform(*log_ratio, N * 10)) | |||||
| # If doesn't satisfy ratio condition, then do central crop | |||||
| w = np.round(np.sqrt(target_area * aspect_ratio)) | |||||
| h = np.round(np.sqrt(target_area / aspect_ratio)) | |||||
| cond = (0 < w) * (w <= width) * (0 < h) * (h <= height) | |||||
| w = w[cond] | |||||
| h = h[cond] | |||||
| cond_len = w.shape[0] | |||||
| if cond_len >= N: | |||||
| w = w[:N] | |||||
| h = h[:N] | |||||
| else: | |||||
| w = np.concatenate([w, np.ones(N - cond_len) * width]) | |||||
| h = np.concatenate([h, np.ones(N - cond_len) * height]) | |||||
| w_bias = np.random.randint(w - width, width - w + 1) / width | |||||
| h_bias = np.random.randint(h - height, height - h + 1) / height | |||||
| w = w / width | |||||
| h = h / height | |||||
| whbias = np.column_stack([w, h, w_bias, h_bias]) | |||||
| whbias = torch.tensor(whbias, device=_device) | |||||
| return whbias | |||||
| class HorizontalFlipRandomCrop(nn.Module): | |||||
| def __init__(self, max_range): | |||||
| super(HorizontalFlipRandomCrop, self).__init__() | |||||
| self.max_range = max_range | |||||
| _eye = torch.eye(2, 3) | |||||
| self.register_buffer('_eye', _eye) | |||||
| def forward(self, input, sign=None, bias=None, rotation=None): | |||||
| _device = input.device | |||||
| N = input.size(0) | |||||
| _theta = self._eye.repeat(N, 1, 1) | |||||
| if sign is None: | |||||
| sign = torch.bernoulli(torch.ones(N, device=_device) * 0.5) * 2 - 1 | |||||
| if bias is None: | |||||
| bias = torch.empty((N, 2), device=_device).uniform_(-self.max_range, self.max_range) | |||||
| _theta[:, 0, 0] = sign | |||||
| _theta[:, :, 2] = bias | |||||
| if rotation is not None: | |||||
| _theta[:, 0:2, 0:2] = rotation | |||||
| grid = F.affine_grid(_theta, input.size(), **kwargs).to(_device) | |||||
| output = F.grid_sample(input, grid, padding_mode='reflection', **kwargs) | |||||
| return output | |||||
| def _sample_latent(self, N, device=None): | |||||
| sign = torch.bernoulli(torch.ones(N, device=device) * 0.5) * 2 - 1 | |||||
| bias = torch.empty((N, 2), device=device).uniform_(-self.max_range, self.max_range) | |||||
| return sign, bias | |||||
| class Rotation(nn.Module): | |||||
| def __init__(self, max_range = 4): | |||||
| super(Rotation, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.prob = 0.5 | |||||
| def forward(self, input, aug_index=None): | |||||
| _device = input.device | |||||
| _, _, H, W = input.size() | |||||
| if aug_index is None: | |||||
| aug_index = np.random.randint(4) | |||||
| output = torch.rot90(input, aug_index, (2, 3)) | |||||
| _prob = input.new_full((input.size(0),), self.prob) | |||||
| _mask = torch.bernoulli(_prob).view(-1, 1, 1, 1) | |||||
| output = _mask * input + (1-_mask) * output | |||||
| else: | |||||
| aug_index = aug_index % self.max_range | |||||
| output = torch.rot90(input, aug_index, (2, 3)) | |||||
| return output | |||||
| class RandomAdjustSharpness(nn.Module): | |||||
| def __init__(self, sharpness_factor=0.5, p=0.5): | |||||
| super(RandomAdjustSharpness, self).__init__() | |||||
| self.sharpness_factor = sharpness_factor | |||||
| self.prob = p | |||||
| def forward(self, input, aug_index=None): | |||||
| _device = input.device | |||||
| _, _, H, W = input.size() | |||||
| if aug_index == 0: | |||||
| output = input | |||||
| else: | |||||
| output = transforms.RandomAdjustSharpness(sharpness_factor=self.sharpness_factor, p=self.prob)(input) | |||||
| return output | |||||
| class RandPers(nn.Module): | |||||
| def __init__(self, distortion_scale=0.5, p=0.5): | |||||
| super(RandPers, self).__init__() | |||||
| self.distortion_scale = distortion_scale | |||||
| self.prob = p | |||||
| def forward(self, input, aug_index=None): | |||||
| _device = input.device | |||||
| _, _, H, W = input.size() | |||||
| if aug_index == 0: | |||||
| output = input | |||||
| else: | |||||
| output = transforms.RandomPerspective(distortion_scale=self.distortion_scale, p=self.prob)(input) | |||||
| return output | |||||
| class GaussBlur(nn.Module): | |||||
| def __init__(self, max_range = 4, kernel_size=3, sigma=(0.1, 2.0)): | |||||
| super(GaussBlur, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.prob = 0.5 | |||||
| self.sigma = sigma | |||||
| self.kernel_size = kernel_size | |||||
| def forward(self, input, aug_index=None): | |||||
| _device = input.device | |||||
| _, _, H, W = input.size() | |||||
| if aug_index is None: | |||||
| aug_index = np.random.randint(4) | |||||
| output = transforms.GaussianBlur(kernel_size=13, sigma=abs(aug_index)+1)(input) | |||||
| _prob = input.new_full((input.size(0),), self.prob) | |||||
| _mask = torch.bernoulli(_prob).view(-1, 1, 1, 1) | |||||
| output = _mask * input + (1-_mask) * output | |||||
| else: | |||||
| if aug_index == 0: | |||||
| output = input | |||||
| else: | |||||
| output = transforms.GaussianBlur(kernel_size=self.kernel_size, sigma=self.sigma)(input) | |||||
| return output | |||||
| class GaussNoise(nn.Module): | |||||
| def __init__(self, mean = 0, std = 1): | |||||
| super(GaussNoise, self).__init__() | |||||
| self.mean = mean | |||||
| self.std = std | |||||
| def forward(self, input, aug_index=None): | |||||
| _device = input.device | |||||
| _, _, H, W = input.size() | |||||
| if aug_index == 0: | |||||
| output = input | |||||
| else: | |||||
| output = input + (torch.randn(input.size()) * self.std + self.mean).to(_device) | |||||
| return output | |||||
| class BlurRandpers(nn.Module): | |||||
| def __init__(self, max_range=2, kernel_size=3, sigma=(10, 20), distortion_scale=0.6, p=1): | |||||
| super(BlurRandpers, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.sigma = sigma | |||||
| self.kernel_size = kernel_size | |||||
| self.distortion_scale = distortion_scale | |||||
| self.p = p | |||||
| self.gauss = GaussBlur(kernel_size=self.kernel_size, sigma=self.sigma) | |||||
| self.randpers = RandPers(distortion_scale=self.distortion_scale, p=self.p) | |||||
| def forward(self, input, aug_index=None): | |||||
| output = self.gauss.forward(input=input, aug_index=aug_index) | |||||
| output = self.randpers.forward(input=output, aug_index=aug_index) | |||||
| return output | |||||
| class BlurSharpness(nn.Module): | |||||
| def __init__(self, max_range=2, kernel_size=3, sigma=(10, 20), sharpness_factor=0.6, p=1): | |||||
| super(BlurSharpness, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.sigma = sigma | |||||
| self.kernel_size = kernel_size | |||||
| self.sharpness_factor = sharpness_factor | |||||
| self.p = p | |||||
| self.gauss = GaussBlur(kernel_size=self.kernel_size, sigma=self.sigma) | |||||
| self.sharp = RandomAdjustSharpness(sharpness_factor=self.sharpness_factor, p=self.p) | |||||
| def forward(self, input, aug_index=None): | |||||
| output = self.gauss.forward(input=input, aug_index=aug_index) | |||||
| output = self.sharp.forward(input=output, aug_index=aug_index) | |||||
| return output | |||||
| class RandpersSharpness(nn.Module): | |||||
| def __init__(self, max_range=2, distortion_scale=0.6, p=1, sharpness_factor=0.6): | |||||
| super(RandpersSharpness, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.distortion_scale = distortion_scale | |||||
| self.p = p | |||||
| self.sharpness_factor = sharpness_factor | |||||
| self.randpers = RandPers(distortion_scale=self.distortion_scale, p=self.p) | |||||
| self.sharp = RandomAdjustSharpness(sharpness_factor=self.sharpness_factor, p=self.p) | |||||
| def forward(self, input, aug_index=None): | |||||
| output = self.randpers.forward(input=input, aug_index=aug_index) | |||||
| output = self.sharp.forward(input=output, aug_index=aug_index) | |||||
| return output | |||||
| class BlurRandpersSharpness(nn.Module): | |||||
| def __init__(self, max_range=2, kernel_size=3, sigma=(10, 20), distortion_scale=0.6, p=1, sharpness_factor=0.6): | |||||
| super(BlurRandpersSharpness, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.sigma = sigma | |||||
| self.kernel_size = kernel_size | |||||
| self.distortion_scale = distortion_scale | |||||
| self.p = p | |||||
| self.sharpness_factor = sharpness_factor | |||||
| self.gauss = GaussBlur(kernel_size=self.kernel_size, sigma=self.sigma) | |||||
| self.randpers = RandPers(distortion_scale=self.distortion_scale, p=self.p) | |||||
| self.sharp = RandomAdjustSharpness(sharpness_factor=self.sharpness_factor, p=self.p) | |||||
| def forward(self, input, aug_index=None): | |||||
| output = self.gauss.forward(input=input, aug_index=aug_index) | |||||
| output = self.randpers.forward(input=output, aug_index=aug_index) | |||||
| output = self.sharp.forward(input=output, aug_index=aug_index) | |||||
| return output | |||||
| class FourCrop(nn.Module): | |||||
| def __init__(self, max_range = 4): | |||||
| super(FourCrop, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.prob = 0.5 | |||||
| def forward(self, inputs): | |||||
| outputs = inputs | |||||
| for i in range(8): | |||||
| outputs[i] = self._crop(inputs.size(), inputs[i], i) | |||||
| return outputs | |||||
| def _crop(self, size, input, i): | |||||
| _, _, H, W = size | |||||
| h_mid = int(H / 2) | |||||
| w_mid = int(W / 2) | |||||
| if i == 0 or i == 4: | |||||
| corner = input[:, 0:h_mid, 0:w_mid] | |||||
| elif i == 1 or i == 5: | |||||
| corner = input[:, 0:h_mid, w_mid:] | |||||
| elif i == 2 or i == 6: | |||||
| corner = input[:, h_mid:, 0:w_mid] | |||||
| elif i == 3 or i == 7: | |||||
| corner = input[:, h_mid:, w_mid:] | |||||
| else: | |||||
| corner = input | |||||
| corner = transforms.Resize(size=2*h_mid)(corner) | |||||
| return corner | |||||
| class CutPerm(nn.Module): | |||||
| def __init__(self, max_range = 4): | |||||
| super(CutPerm, self).__init__() | |||||
| self.max_range = max_range | |||||
| self.prob = 0.5 | |||||
| def forward(self, input, aug_index=None): | |||||
| _device = input.device | |||||
| _, _, H, W = input.size() | |||||
| if aug_index is None: | |||||
| aug_index = np.random.randint(4) | |||||
| output = self._cutperm(input, aug_index) | |||||
| _prob = input.new_full((input.size(0),), self.prob) | |||||
| _mask = torch.bernoulli(_prob).view(-1, 1, 1, 1) | |||||
| output = _mask * input + (1 - _mask) * output | |||||
| else: | |||||
| aug_index = aug_index % self.max_range | |||||
| output = self._cutperm(input, aug_index) | |||||
| return output | |||||
| def _cutperm(self, inputs, aug_index): | |||||
| _, _, H, W = inputs.size() | |||||
| h_mid = int(H / 2) | |||||
| w_mid = int(W / 2) | |||||
| jigsaw_h = aug_index // 2 | |||||
| jigsaw_v = aug_index % 2 | |||||
| if jigsaw_h == 1: | |||||
| inputs = torch.cat((inputs[:, :, h_mid:, :], inputs[:, :, 0:h_mid, :]), dim=2) | |||||
| if jigsaw_v == 1: | |||||
| inputs = torch.cat((inputs[:, :, :, w_mid:], inputs[:, :, :, 0:w_mid]), dim=3) | |||||
| return inputs | |||||
| def assemble(a, b, c, d): | |||||
| ab = torch.cat((a, b), dim=2) | |||||
| cd = torch.cat((c, d), dim=2) | |||||
| output = torch.cat((ab, cd), dim=3) | |||||
| return output | |||||
| def quarter(inputs): | |||||
| _, _, H, W = inputs.size() | |||||
| h_mid = int(H / 2) | |||||
| w_mid = int(W / 2) | |||||
| quarters = [] | |||||
| quarters.append(inputs[:, :, 0:h_mid, 0:w_mid]) | |||||
| quarters.append(inputs[:, :, 0:h_mid, w_mid:]) | |||||
| quarters.append(inputs[:, :, h_mid:, 0:w_mid]) | |||||
| quarters.append(inputs[:, :, h_mid:, w_mid:]) | |||||
| return quarters | |||||
| class HorizontalFlipLayer(nn.Module): | |||||
| def __init__(self): | |||||
| """ | |||||
| img_size : (int, int, int) | |||||
| Height and width must be powers of 2. E.g. (32, 32, 1) or | |||||
| (64, 128, 3). Last number indicates number of channels, e.g. 1 for | |||||
| grayscale or 3 for RGB | |||||
| """ | |||||
| super(HorizontalFlipLayer, self).__init__() | |||||
| _eye = torch.eye(2, 3) | |||||
| self.register_buffer('_eye', _eye) | |||||
| def forward(self, inputs): | |||||
| _device = inputs.device | |||||
| N = inputs.size(0) | |||||
| _theta = self._eye.repeat(N, 1, 1) | |||||
| r_sign = torch.bernoulli(torch.ones(N, device=_device) * 0.5) * 2 - 1 | |||||
| _theta[:, 0, 0] = r_sign | |||||
| grid = F.affine_grid(_theta, inputs.size(), **kwargs).to(_device) | |||||
| inputs = F.grid_sample(inputs, grid, padding_mode='reflection', **kwargs) | |||||
| return inputs | |||||
| class RandomColorGrayLayer(nn.Module): | |||||
| def __init__(self, p): | |||||
| super(RandomColorGrayLayer, self).__init__() | |||||
| self.prob = p | |||||
| _weight = torch.tensor([[0.299, 0.587, 0.114]]) | |||||
| self.register_buffer('_weight', _weight.view(1, 3, 1, 1)) | |||||
| def forward(self, inputs, aug_index=None): | |||||
| if aug_index == 0: | |||||
| return inputs | |||||
| l = F.conv2d(inputs, self._weight) | |||||
| gray = torch.cat([l, l, l], dim=1) | |||||
| if aug_index is None: | |||||
| _prob = inputs.new_full((inputs.size(0),), self.prob) | |||||
| _mask = torch.bernoulli(_prob).view(-1, 1, 1, 1) | |||||
| gray = inputs * (1 - _mask) + gray * _mask | |||||
| return gray | |||||
| class ColorJitterLayer(nn.Module): | |||||
| def __init__(self, p, brightness, contrast, saturation, hue): | |||||
| super(ColorJitterLayer, self).__init__() | |||||
| self.prob = p | |||||
| self.brightness = self._check_input(brightness, 'brightness') | |||||
| self.contrast = self._check_input(contrast, 'contrast') | |||||
| self.saturation = self._check_input(saturation, 'saturation') | |||||
| self.hue = self._check_input(hue, 'hue', center=0, bound=(-0.5, 0.5), | |||||
| clip_first_on_zero=False) | |||||
| def _check_input(self, value, name, center=1, bound=(0, float('inf')), clip_first_on_zero=True): | |||||
| if isinstance(value, numbers.Number): | |||||
| if value < 0: | |||||
| raise ValueError("If {} is a single number, it must be non negative.".format(name)) | |||||
| value = [center - value, center + value] | |||||
| if clip_first_on_zero: | |||||
| value[0] = max(value[0], 0) | |||||
| elif isinstance(value, (tuple, list)) and len(value) == 2: | |||||
| if not bound[0] <= value[0] <= value[1] <= bound[1]: | |||||
| raise ValueError("{} values should be between {}".format(name, bound)) | |||||
| else: | |||||
| raise TypeError("{} should be a single number or a list/tuple with lenght 2.".format(name)) | |||||
| # if value is 0 or (1., 1.) for brightness/contrast/saturation | |||||
| # or (0., 0.) for hue, do nothing | |||||
| if value[0] == value[1] == center: | |||||
| value = None | |||||
| return value | |||||
| def adjust_contrast(self, x): | |||||
| if self.contrast: | |||||
| factor = x.new_empty(x.size(0), 1, 1, 1).uniform_(*self.contrast) | |||||
| means = torch.mean(x, dim=[2, 3], keepdim=True) | |||||
| x = (x - means) * factor + means | |||||
| return torch.clamp(x, 0, 1) | |||||
| def adjust_hsv(self, x): | |||||
| f_h = x.new_zeros(x.size(0), 1, 1) | |||||
| f_s = x.new_ones(x.size(0), 1, 1) | |||||
| f_v = x.new_ones(x.size(0), 1, 1) | |||||
| if self.hue: | |||||
| f_h.uniform_(*self.hue) | |||||
| if self.saturation: | |||||
| f_s = f_s.uniform_(*self.saturation) | |||||
| if self.brightness: | |||||
| f_v = f_v.uniform_(*self.brightness) | |||||
| return RandomHSVFunction.apply(x, f_h, f_s, f_v) | |||||
| def transform(self, inputs): | |||||
| # Shuffle transform | |||||
| if np.random.rand() > 0.5: | |||||
| transforms = [self.adjust_contrast, self.adjust_hsv] | |||||
| else: | |||||
| transforms = [self.adjust_hsv, self.adjust_contrast] | |||||
| for t in transforms: | |||||
| inputs = t(inputs) | |||||
| return inputs | |||||
| def forward(self, inputs): | |||||
| _prob = inputs.new_full((inputs.size(0),), self.prob) | |||||
| _mask = torch.bernoulli(_prob).view(-1, 1, 1, 1) | |||||
| return inputs * (1 - _mask) + self.transform(inputs) * _mask | |||||
| class RandomHSVFunction(Function): | |||||
| @staticmethod | |||||
| def forward(ctx, x, f_h, f_s, f_v): | |||||
| # ctx is a context object that can be used to stash information | |||||
| # for backward computation | |||||
| x = rgb2hsv(x) | |||||
| h = x[:, 0, :, :] | |||||
| h += (f_h * 255. / 360.) | |||||
| h = (h % 1) | |||||
| x[:, 0, :, :] = h | |||||
| x[:, 1, :, :] = x[:, 1, :, :] * f_s | |||||
| x[:, 2, :, :] = x[:, 2, :, :] * f_v | |||||
| x = torch.clamp(x, 0, 1) | |||||
| x = hsv2rgb(x) | |||||
| return x | |||||
| @staticmethod | |||||
| def backward(ctx, grad_output): | |||||
| # We return as many input gradients as there were arguments. | |||||
| # Gradients of non-Tensor arguments to forward must be None. | |||||
| grad_input = None | |||||
| if ctx.needs_input_grad[0]: | |||||
| grad_input = grad_output.clone() | |||||
| return grad_input, None, None, None | |||||
| class NormalizeLayer(nn.Module): | |||||
| """ | |||||
| In order to certify radii in original coordinates rather than standardized coordinates, we | |||||
| add the Gaussian noise _before_ standardizing, which is why we have standardization be the first | |||||
| layer of the classifier rather than as a part of preprocessing as is typical. | |||||
| """ | |||||
| def __init__(self): | |||||
| super(NormalizeLayer, self).__init__() | |||||
| def forward(self, inputs): | |||||
| return (inputs - 0.5) / 0.5 | |||||
+ 1799
- 0
train.ipynb
File diff suppressed because it is too large
View File
+ 57
- 0
train.py
View File
| from utils.utils import Logger | |||||
| from utils.utils import save_checkpoint | |||||
| from utils.utils import save_linear_checkpoint | |||||
| from common.train import * | |||||
| from evals import test_classifier | |||||
| if 'sup' in P.mode: | |||||
| from training.sup import setup | |||||
| else: | |||||
| from training.unsup import setup | |||||
| train, fname = setup(P.mode, P) | |||||
| logger = Logger(fname, ask=not resume, local_rank=P.local_rank) | |||||
| logger.log(P) | |||||
| logger.log(model) | |||||
| if P.multi_gpu: | |||||
| linear = model.module.linear | |||||
| else: | |||||
| linear = model.linear | |||||
| linear_optim = torch.optim.Adam(linear.parameters(), lr=1e-3, betas=(.9, .999), weight_decay=P.weight_decay) | |||||
| # Run experiments | |||||
| for epoch in range(start_epoch, P.epochs + 1): | |||||
| logger.log_dirname(f"Epoch {epoch}") | |||||
| model.train() | |||||
| if P.multi_gpu: | |||||
| train_sampler.set_epoch(epoch) | |||||
| kwargs = {} | |||||
| kwargs['linear'] = linear | |||||
| kwargs['linear_optim'] = linear_optim | |||||
| kwargs['simclr_aug'] = simclr_aug | |||||
| train(P, epoch, model, criterion, optimizer, scheduler_warmup, train_loader, logger=logger, **kwargs) | |||||
| model.eval() | |||||
| if epoch % P.save_step == 0 and P.local_rank == 0: | |||||
| if P.multi_gpu: | |||||
| save_states = model.module.state_dict() | |||||
| else: | |||||
| save_states = model.state_dict() | |||||
| save_checkpoint(epoch, save_states, optimizer.state_dict(), logger.logdir) | |||||
| save_linear_checkpoint(linear_optim.state_dict(), logger.logdir) | |||||
| if epoch % P.error_step == 0 and ('sup' in P.mode): | |||||
| error = test_classifier(P, model, test_loader, epoch, logger=logger) | |||||
| is_best = (best > error) | |||||
| if is_best: | |||||
| best = error | |||||
| logger.scalar_summary('eval/best_error', best, epoch) | |||||
| logger.log('[Epoch %3d] [Test %5.2f] [Best %5.2f]' % (epoch, error, best)) |
+ 97
- 0
training/__init__.py
View File
| import torch | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| def update_learning_rate(P, optimizer, cur_epoch, n, n_total): | |||||
| cur_epoch = cur_epoch - 1 | |||||
| lr = P.lr_init | |||||
| if P.optimizer == 'sgd' or 'lars': | |||||
| DECAY_RATIO = 0.1 | |||||
| elif P.optimizer == 'adam': | |||||
| DECAY_RATIO = 0.3 | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| if P.warmup > 0: | |||||
| cur_iter = cur_epoch * n_total + n | |||||
| if cur_iter <= P.warmup: | |||||
| lr *= cur_iter / float(P.warmup) | |||||
| if cur_epoch >= 0.5 * P.epochs: | |||||
| lr *= DECAY_RATIO | |||||
| if cur_epoch >= 0.75 * P.epochs: | |||||
| lr *= DECAY_RATIO | |||||
| for param_group in optimizer.param_groups: | |||||
| param_group['lr'] = lr | |||||
| return lr | |||||
| def _cross_entropy(input, targets, reduction='mean'): | |||||
| targets_prob = F.softmax(targets, dim=1) | |||||
| xent = (-targets_prob * F.log_softmax(input, dim=1)).sum(1) | |||||
| if reduction == 'sum': | |||||
| return xent.sum() | |||||
| elif reduction == 'mean': | |||||
| return xent.mean() | |||||
| elif reduction == 'none': | |||||
| return xent | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| def _entropy(input, reduction='mean'): | |||||
| return _cross_entropy(input, input, reduction) | |||||
| def cross_entropy_soft(input, targets, reduction='mean'): | |||||
| targets_prob = F.softmax(targets, dim=1) | |||||
| xent = (-targets_prob * F.log_softmax(input, dim=1)).sum(1) | |||||
| if reduction == 'sum': | |||||
| return xent.sum() | |||||
| elif reduction == 'mean': | |||||
| return xent.mean() | |||||
| elif reduction == 'none': | |||||
| return xent | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| def kl_div(input, targets, reduction='batchmean'): | |||||
| return F.kl_div(F.log_softmax(input, dim=1), F.softmax(targets, dim=1), | |||||
| reduction=reduction) | |||||
| def target_nll_loss(inputs, targets, reduction='none'): | |||||
| inputs_t = -F.nll_loss(inputs, targets, reduction='none') | |||||
| logit_diff = inputs - inputs_t.view(-1, 1) | |||||
| logit_diff = logit_diff.scatter(1, targets.view(-1, 1), -1e8) | |||||
| diff_max = logit_diff.max(1)[0] | |||||
| if reduction == 'sum': | |||||
| return diff_max.sum() | |||||
| elif reduction == 'mean': | |||||
| return diff_max.mean() | |||||
| elif reduction == 'none': | |||||
| return diff_max | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| def target_nll_c(inputs, targets, reduction='none'): | |||||
| conf = torch.softmax(inputs, dim=1) | |||||
| conf_t = -F.nll_loss(conf, targets, reduction='none') | |||||
| conf_diff = conf - conf_t.view(-1, 1) | |||||
| conf_diff = conf_diff.scatter(1, targets.view(-1, 1), -1) | |||||
| diff_max = conf_diff.max(1)[0] | |||||
| if reduction == 'sum': | |||||
| return diff_max.sum() | |||||
| elif reduction == 'mean': | |||||
| return diff_max.mean() | |||||
| elif reduction == 'none': | |||||
| return diff_max | |||||
| else: | |||||
| raise NotImplementedError() |
BIN
training/__pycache__/__init__.cpython-36.pyc
View File
BIN
training/__pycache__/__init__.cpython-37.pyc
View File
BIN
training/__pycache__/contrastive_loss.cpython-36.pyc
View File
BIN
training/__pycache__/contrastive_loss.cpython-37.pyc
View File
BIN
training/__pycache__/scheduler.cpython-36.pyc
View File
BIN
training/__pycache__/scheduler.cpython-37.pyc
View File
+ 79
- 0
training/contrastive_loss.py
View File
| import torch | |||||
| import torch.distributed as dist | |||||
| import diffdist.functional as distops | |||||
| def get_similarity_matrix(outputs, chunk=2, multi_gpu=False): | |||||
| ''' | |||||
| Compute similarity matrix | |||||
| - outputs: (B', d) tensor for B' = B * chunk | |||||
| - sim_matrix: (B', B') tensor | |||||
| ''' | |||||
| if multi_gpu: | |||||
| outputs_gathered = [] | |||||
| for out in outputs.chunk(chunk): | |||||
| gather_t = [torch.empty_like(out) for _ in range(dist.get_world_size())] | |||||
| gather_t = torch.cat(distops.all_gather(gather_t, out)) | |||||
| outputs_gathered.append(gather_t) | |||||
| outputs = torch.cat(outputs_gathered) | |||||
| sim_matrix = torch.mm(outputs, outputs.t()) # (B', d), (d, B') -> (B', B') | |||||
| return sim_matrix | |||||
| def NT_xent(sim_matrix, temperature=0.5, chunk=2, eps=1e-8): | |||||
| ''' | |||||
| Compute NT_xent loss | |||||
| - sim_matrix: (B', B') tensor for B' = B * chunk (first 2B are pos samples) | |||||
| ''' | |||||
| device = sim_matrix.device | |||||
| B = sim_matrix.size(0) // chunk # B = B' / chunk | |||||
| eye = torch.eye(B * chunk).to(device) # (B', B') | |||||
| sim_matrix = torch.exp(sim_matrix / temperature) * (1 - eye) # remove diagonal | |||||
| denom = torch.sum(sim_matrix, dim=1, keepdim=True) | |||||
| sim_matrix = -torch.log(sim_matrix / (denom + eps) + eps) # loss matrix | |||||
| loss = torch.sum(sim_matrix[:B, B:].diag() + sim_matrix[B:, :B].diag()) / (2 * B) | |||||
| return loss | |||||
| def Supervised_NT_xent(sim_matrix, labels, temperature=0.5, chunk=2, eps=1e-8, multi_gpu=False): | |||||
| ''' | |||||
| Compute NT_xent loss | |||||
| - sim_matrix: (B', B') tensor for B' = B * chunk (first 2B are pos samples) | |||||
| ''' | |||||
| device = sim_matrix.device | |||||
| if multi_gpu: | |||||
| gather_t = [torch.empty_like(labels) for _ in range(dist.get_world_size())] | |||||
| labels = torch.cat(distops.all_gather(gather_t, labels)) | |||||
| labels = labels.repeat(2) | |||||
| logits_max, _ = torch.max(sim_matrix, dim=1, keepdim=True) | |||||
| sim_matrix = sim_matrix - logits_max.detach() | |||||
| B = sim_matrix.size(0) // chunk # B = B' / chunk | |||||
| eye = torch.eye(B * chunk).to(device) # (B', B') | |||||
| sim_matrix = torch.exp(sim_matrix / temperature) * (1 - eye) # remove diagonal | |||||
| denom = torch.sum(sim_matrix, dim=1, keepdim=True) | |||||
| sim_matrix = -torch.log(sim_matrix / (denom + eps) + eps) # loss matrix | |||||
| labels = labels.contiguous().view(-1, 1) | |||||
| Mask = torch.eq(labels, labels.t()).float().to(device) | |||||
| #Mask = eye * torch.stack([labels == labels[i] for i in range(labels.size(0))]).float().to(device) | |||||
| Mask = Mask / (Mask.sum(dim=1, keepdim=True) + eps) | |||||
| loss = torch.sum(Mask * sim_matrix) / (2 * B) | |||||
| return loss | |||||
+ 63
- 0
training/scheduler.py
View File
| from torch.optim.lr_scheduler import _LRScheduler | |||||
| from torch.optim.lr_scheduler import ReduceLROnPlateau | |||||
| class GradualWarmupScheduler(_LRScheduler): | |||||
| """ Gradually warm-up(increasing) learning rate in optimizer. | |||||
| Proposed in 'Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour'. | |||||
| Args: | |||||
| optimizer (Optimizer): Wrapped optimizer. | |||||
| multiplier: target learning rate = base lr * multiplier if multiplier > 1.0. if multiplier = 1.0, lr starts from 0 and ends up with the base_lr. | |||||
| total_epoch: target learning rate is reached at total_epoch, gradually | |||||
| after_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau) | |||||
| """ | |||||
| def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None): | |||||
| self.multiplier = multiplier | |||||
| if self.multiplier < 1.: | |||||
| raise ValueError('multiplier should be greater thant or equal to 1.') | |||||
| self.total_epoch = total_epoch | |||||
| self.after_scheduler = after_scheduler | |||||
| self.finished = False | |||||
| super(GradualWarmupScheduler, self).__init__(optimizer) | |||||
| def get_lr(self): | |||||
| if self.last_epoch > self.total_epoch: | |||||
| if self.after_scheduler: | |||||
| if not self.finished: | |||||
| self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs] | |||||
| self.finished = True | |||||
| return self.after_scheduler.get_lr() | |||||
| return [base_lr * self.multiplier for base_lr in self.base_lrs] | |||||
| if self.multiplier == 1.0: | |||||
| return [base_lr * (float(self.last_epoch) / self.total_epoch) for base_lr in self.base_lrs] | |||||
| else: | |||||
| return [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs] | |||||
| def step_ReduceLROnPlateau(self, metrics, epoch=None): | |||||
| if epoch is None: | |||||
| epoch = self.last_epoch + 1 | |||||
| self.last_epoch = epoch if epoch != 0 else 1 # ReduceLROnPlateau is called at the end of epoch, whereas others are called at beginning | |||||
| if self.last_epoch <= self.total_epoch: | |||||
| warmup_lr = [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs] | |||||
| for param_group, lr in zip(self.optimizer.param_groups, warmup_lr): | |||||
| param_group['lr'] = lr | |||||
| else: | |||||
| if epoch is None: | |||||
| self.after_scheduler.step(metrics, None) | |||||
| else: | |||||
| self.after_scheduler.step(metrics, epoch - self.total_epoch) | |||||
| def step(self, epoch=None, metrics=None): | |||||
| if type(self.after_scheduler) != ReduceLROnPlateau: | |||||
| if self.finished and self.after_scheduler: | |||||
| if epoch is None: | |||||
| self.after_scheduler.step(None) | |||||
| else: | |||||
| self.after_scheduler.step(epoch - self.total_epoch) | |||||
| else: | |||||
| return super(GradualWarmupScheduler, self).step(epoch) | |||||
| else: | |||||
| self.step_ReduceLROnPlateau(metrics, epoch) |
+ 33
- 0
training/sup/__init__.py
View File
| def setup(mode, P): | |||||
| fname = f'{P.dataset}_{P.model}_{mode}_{P.res}' | |||||
| if mode == 'sup_linear': | |||||
| from .sup_linear import train | |||||
| elif mode == 'sup_CSI_linear': | |||||
| from .sup_CSI_linear import train | |||||
| elif mode == 'sup_simclr': | |||||
| from .sup_simclr import train | |||||
| elif mode == 'sup_simclr_CSI': | |||||
| assert P.batch_size == 32 | |||||
| # currently only support rotation | |||||
| from .sup_simclr_CSI import train | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| if P.suffix is not None: | |||||
| fname += f'_{P.suffix}' | |||||
| return train, fname | |||||
| def update_comp_loss(loss_dict, loss_in, loss_out, loss_diff, batch_size): | |||||
| loss_dict['pos'].update(loss_in, batch_size) | |||||
| loss_dict['neg'].update(loss_out, batch_size) | |||||
| loss_dict['diff'].update(loss_diff, batch_size) | |||||
| def summary_comp_loss(logger, tag, loss_dict, epoch): | |||||
| logger.scalar_summary(f'{tag}/pos', loss_dict['pos'].average, epoch) | |||||
| logger.scalar_summary(f'{tag}/neg', loss_dict['neg'].average, epoch) | |||||
| logger.scalar_summary(f'{tag}', loss_dict['diff'].average, epoch) | |||||
BIN
training/sup/__pycache__/__init__.cpython-36.pyc
View File
BIN
training/sup/__pycache__/sup_simclr.cpython-36.pyc
View File
BIN
training/sup/__pycache__/sup_simclr_CSI.cpython-36.pyc
View File
+ 130
- 0
training/sup/sup_CSI_linear.py
View File
| import time | |||||
| import torch.optim | |||||
| import torch.optim.lr_scheduler as lr_scheduler | |||||
| import models.transform_layers as TL | |||||
| from utils.utils import AverageMeter, normalize | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| hflip = TL.HorizontalFlipLayer().to(device) | |||||
| def train(P, epoch, model, criterion, optimizer, scheduler, loader, logger=None, | |||||
| simclr_aug=None, linear=None, linear_optim=None): | |||||
| if P.multi_gpu: | |||||
| rotation_linear = model.module.shift_cls_layer | |||||
| joint_linear = model.module.joint_distribution_layer | |||||
| else: | |||||
| rotation_linear = model.shift_cls_layer | |||||
| joint_linear = model.joint_distribution_layer | |||||
| if epoch == 1: | |||||
| # define optimizer and save in P (argument) | |||||
| milestones = [int(0.6 * P.epochs), int(0.75 * P.epochs), int(0.9 * P.epochs)] | |||||
| linear_optim = torch.optim.SGD(linear.parameters(), | |||||
| lr=1e-1, weight_decay=P.weight_decay) | |||||
| P.linear_optim = linear_optim | |||||
| P.linear_scheduler = lr_scheduler.MultiStepLR(P.linear_optim, gamma=0.1, milestones=milestones) | |||||
| rotation_linear_optim = torch.optim.SGD(rotation_linear.parameters(), | |||||
| lr=1e-1, weight_decay=P.weight_decay) | |||||
| P.rotation_linear_optim = rotation_linear_optim | |||||
| P.rot_scheduler = lr_scheduler.MultiStepLR(P.rotation_linear_optim, gamma=0.1, milestones=milestones) | |||||
| joint_linear_optim = torch.optim.SGD(joint_linear.parameters(), | |||||
| lr=1e-1, weight_decay=P.weight_decay) | |||||
| P.joint_linear_optim = joint_linear_optim | |||||
| P.joint_scheduler = lr_scheduler.MultiStepLR(P.joint_linear_optim, gamma=0.1, milestones=milestones) | |||||
| if logger is None: | |||||
| log_ = print | |||||
| else: | |||||
| log_ = logger.log | |||||
| batch_time = AverageMeter() | |||||
| data_time = AverageMeter() | |||||
| losses = dict() | |||||
| losses['cls'] = AverageMeter() | |||||
| losses['rot'] = AverageMeter() | |||||
| check = time.time() | |||||
| for n, (images, labels) in enumerate(loader): | |||||
| model.eval() | |||||
| count = n * P.n_gpus # number of trained samples | |||||
| data_time.update(time.time() - check) | |||||
| check = time.time() | |||||
| ### SimCLR loss ### | |||||
| if P.dataset != 'imagenet': | |||||
| batch_size = images.size(0) | |||||
| images = images.to(device) | |||||
| images = hflip(images) # 2B with hflip | |||||
| else: | |||||
| batch_size = images[0].size(0) | |||||
| images = images[0].to(device) | |||||
| labels = labels.to(device) | |||||
| images = torch.cat([torch.rot90(images, rot, (2, 3)) for rot in range(4)]) # 4B | |||||
| rot_labels = torch.cat([torch.ones_like(labels) * k for k in range(4)], 0) # B -> 4B | |||||
| joint_labels = torch.cat([labels + P.n_classes * i for i in range(4)], dim=0) | |||||
| images = simclr_aug(images) # simclr augmentation | |||||
| _, outputs_aux = model(images, penultimate=True) | |||||
| penultimate = outputs_aux['penultimate'].detach() | |||||
| outputs = linear(penultimate[0:batch_size]) # only use 0 degree samples for linear eval | |||||
| outputs_rot = rotation_linear(penultimate) | |||||
| outputs_joint = joint_linear(penultimate) | |||||
| loss_ce = criterion(outputs, labels) | |||||
| loss_rot = criterion(outputs_rot, rot_labels) | |||||
| loss_joint = criterion(outputs_joint, joint_labels) | |||||
| ### CE loss ### | |||||
| P.linear_optim.zero_grad() | |||||
| loss_ce.backward() | |||||
| P.linear_optim.step() | |||||
| ### Rot loss ### | |||||
| P.rotation_linear_optim.zero_grad() | |||||
| loss_rot.backward() | |||||
| P.rotation_linear_optim.step() | |||||
| ### Joint loss ### | |||||
| P.joint_linear_optim.zero_grad() | |||||
| loss_joint.backward() | |||||
| P.joint_linear_optim.step() | |||||
| ### optimizer learning rate ### | |||||
| lr = P.linear_optim.param_groups[0]['lr'] | |||||
| batch_time.update(time.time() - check) | |||||
| ### Log losses ### | |||||
| losses['cls'].update(loss_ce.item(), batch_size) | |||||
| losses['rot'].update(loss_rot.item(), batch_size) | |||||
| if count % 50 == 0: | |||||
| log_('[Epoch %3d; %3d] [Time %.3f] [Data %.3f] [LR %.5f]\n' | |||||
| '[LossC %f] [LossR %f]' % | |||||
| (epoch, count, batch_time.value, data_time.value, lr, | |||||
| losses['cls'].value, losses['rot'].value)) | |||||
| check = time.time() | |||||
| P.linear_scheduler.step() | |||||
| P.rot_scheduler.step() | |||||
| P.joint_scheduler.step() | |||||
| log_('[DONE] [Time %.3f] [Data %.3f] [LossC %f] [LossR %f]' % | |||||
| (batch_time.average, data_time.average, | |||||
| losses['cls'].average, losses['rot'].average)) | |||||
| if logger is not None: | |||||
| logger.scalar_summary('train/loss_cls', losses['cls'].average, epoch) | |||||
| logger.scalar_summary('train/loss_rot', losses['rot'].average, epoch) | |||||
| logger.scalar_summary('train/batch_time', batch_time.average, epoch) |
+ 91
- 0
training/sup/sup_linear.py
View File
| import time | |||||
| import torch.optim | |||||
| import torch.optim.lr_scheduler as lr_scheduler | |||||
| import models.transform_layers as TL | |||||
| from utils.utils import AverageMeter, normalize | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| hflip = TL.HorizontalFlipLayer().to(device) | |||||
| def train(P, epoch, model, criterion, optimizer, scheduler, loader, logger=None, | |||||
| simclr_aug=None, linear=None, linear_optim=None): | |||||
| if epoch == 1: | |||||
| # define optimizer and save in P (argument) | |||||
| milestones = [int(0.6 * P.epochs), int(0.75 * P.epochs), int(0.9 * P.epochs)] | |||||
| linear_optim = torch.optim.SGD(linear.parameters(), | |||||
| lr=1e-1, weight_decay=P.weight_decay) | |||||
| P.linear_optim = linear_optim | |||||
| P.linear_scheduler = lr_scheduler.MultiStepLR(P.linear_optim, gamma=0.1, milestones=milestones) | |||||
| if logger is None: | |||||
| log_ = print | |||||
| else: | |||||
| log_ = logger.log | |||||
| batch_time = AverageMeter() | |||||
| data_time = AverageMeter() | |||||
| losses = dict() | |||||
| losses['cls'] = AverageMeter() | |||||
| check = time.time() | |||||
| for n, (images, labels) in enumerate(loader): | |||||
| model.eval() | |||||
| count = n * P.n_gpus # number of trained samples | |||||
| data_time.update(time.time() - check) | |||||
| check = time.time() | |||||
| ### SimCLR loss ### | |||||
| if P.dataset != 'imagenet': | |||||
| batch_size = images.size(0) | |||||
| images = images.to(device) | |||||
| images = hflip(images) # 2B with hflip | |||||
| else: | |||||
| batch_size = images[0].size(0) | |||||
| images = images[0].to(device) | |||||
| labels = labels.to(device) | |||||
| images = simclr_aug(images) # simclr augmentation | |||||
| _, outputs_aux = model(images, penultimate=True) | |||||
| penultimate = outputs_aux['penultimate'].detach() | |||||
| outputs = linear(penultimate[0:batch_size]) # only use 0 degree samples for linear eval | |||||
| loss_ce = criterion(outputs, labels) | |||||
| ### CE loss ### | |||||
| P.linear_optim.zero_grad() | |||||
| loss_ce.backward() | |||||
| P.linear_optim.step() | |||||
| ### optimizer learning rate ### | |||||
| lr = P.linear_optim.param_groups[0]['lr'] | |||||
| batch_time.update(time.time() - check) | |||||
| ### Log losses ### | |||||
| losses['cls'].update(loss_ce.item(), batch_size) | |||||
| if count % 50 == 0: | |||||
| log_('[Epoch %3d; %3d] [Time %.3f] [Data %.3f] [LR %.5f]\n' | |||||
| '[LossC %f]' % | |||||
| (epoch, count, batch_time.value, data_time.value, lr, | |||||
| losses['cls'].value, )) | |||||
| check = time.time() | |||||
| P.linear_scheduler.step() | |||||
| log_('[DONE] [Time %.3f] [Data %.3f] [LossC %f]' % | |||||
| (batch_time.average, data_time.average, | |||||
| losses['cls'].average)) | |||||
| if logger is not None: | |||||
| logger.scalar_summary('train/loss_cls', losses['cls'].average, epoch) | |||||
| logger.scalar_summary('train/batch_time', batch_time.average, epoch) |
+ 104
- 0
training/sup/sup_simclr.py
View File
| import time | |||||
| import torch.optim | |||||
| import models.transform_layers as TL | |||||
| from training.contrastive_loss import get_similarity_matrix, Supervised_NT_xent | |||||
| from utils.utils import AverageMeter, normalize | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| hflip = TL.HorizontalFlipLayer().to(device) | |||||
| def train(P, epoch, model, criterion, optimizer, scheduler, loader, logger=None, | |||||
| simclr_aug=None, linear=None, linear_optim=None): | |||||
| assert simclr_aug is not None | |||||
| assert P.sim_lambda == 1.0 | |||||
| if logger is None: | |||||
| log_ = print | |||||
| else: | |||||
| log_ = logger.log | |||||
| batch_time = AverageMeter() | |||||
| data_time = AverageMeter() | |||||
| losses = dict() | |||||
| losses['cls'] = AverageMeter() | |||||
| losses['sim'] = AverageMeter() | |||||
| losses['simnorm'] = AverageMeter() | |||||
| check = time.time() | |||||
| for n, (images, labels) in enumerate(loader): | |||||
| model.train() | |||||
| count = n * P.n_gpus # number of trained samples | |||||
| data_time.update(time.time() - check) | |||||
| check = time.time() | |||||
| ### SimCLR loss ### | |||||
| if P.dataset != 'imagenet' and P.dataset != 'CNMC' and P.dataset != 'CNMC_grayscale': | |||||
| batch_size = images.size(0) | |||||
| images = images.to(device) | |||||
| images_pair = hflip(images.repeat(2, 1, 1, 1)) # 2B with hflip | |||||
| else: | |||||
| batch_size = images[0].size(0) | |||||
| images1, images2 = images[0].to(device), images[1].to(device) | |||||
| images_pair = torch.cat([images1, images2], dim=0) # 2B | |||||
| labels = labels.to(device) | |||||
| images_pair = simclr_aug(images_pair) # simclr augmentation | |||||
| _, outputs_aux = model(images_pair, simclr=True, penultimate=True) | |||||
| simclr = normalize(outputs_aux['simclr']) # normalize | |||||
| sim_matrix = get_similarity_matrix(simclr, multi_gpu=P.multi_gpu) | |||||
| loss_sim = Supervised_NT_xent(sim_matrix, labels=labels, temperature=0.07, multi_gpu=P.multi_gpu) * P.sim_lambda | |||||
| ### total loss ### | |||||
| loss = loss_sim | |||||
| optimizer.zero_grad() | |||||
| loss.backward() | |||||
| optimizer.step() | |||||
| scheduler.step(epoch - 1 + n / len(loader)) | |||||
| lr = optimizer.param_groups[0]['lr'] | |||||
| batch_time.update(time.time() - check) | |||||
| ### Post-processing stuffs ### | |||||
| simclr_norm = outputs_aux['simclr'].norm(dim=1).mean() | |||||
| ### Linear evaluation ### | |||||
| outputs_linear_eval = linear(outputs_aux['penultimate'].detach()) | |||||
| loss_linear = criterion(outputs_linear_eval, labels.repeat(2)) | |||||
| linear_optim.zero_grad() | |||||
| loss_linear.backward() | |||||
| linear_optim.step() | |||||
| ### Log losses ### | |||||
| losses['cls'].update(0, batch_size) | |||||
| losses['sim'].update(loss_sim.item(), batch_size) | |||||
| losses['simnorm'].update(simclr_norm.item(), batch_size) | |||||
| if count % 50 == 0: | |||||
| log_('[Epoch %3d; %3d] [Time %.3f] [Data %.3f] [LR %.5f]\n' | |||||
| '[LossC %f] [LossSim %f] [SimNorm %f]' % | |||||
| (epoch, count, batch_time.value, data_time.value, lr, | |||||
| losses['cls'].value, losses['sim'].value, losses['simnorm'].value)) | |||||
| check = time.time() | |||||
| log_('[DONE] [Time %.3f] [Data %.3f] [LossC %f] [LossSim %f] [SimNorm %f]' % | |||||
| (batch_time.average, data_time.average, | |||||
| losses['cls'].average, losses['sim'].average, losses['simnorm'].average)) | |||||
| if logger is not None: | |||||
| logger.scalar_summary('train/loss_cls', losses['cls'].average, epoch) | |||||
| logger.scalar_summary('train/loss_sim', losses['sim'].average, epoch) | |||||
| logger.scalar_summary('train/batch_time', batch_time.average, epoch) | |||||
| logger.scalar_summary('train/simclr_norm', losses['simnorm'].average, epoch) |
+ 111
- 0
training/sup/sup_simclr_CSI.py
View File
| import time | |||||
| import torch.optim | |||||
| import models.transform_layers as TL | |||||
| from training.contrastive_loss import get_similarity_matrix, Supervised_NT_xent | |||||
| from utils.utils import AverageMeter, normalize | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| hflip = TL.HorizontalFlipLayer().to(device) | |||||
| def train(P, epoch, model, criterion, optimizer, scheduler, loader, logger=None, | |||||
| simclr_aug=None, linear=None, linear_optim=None): | |||||
| # currently only support rotation shifting augmentation | |||||
| assert simclr_aug is not None | |||||
| assert P.sim_lambda == 1.0 | |||||
| if logger is None: | |||||
| log_ = print | |||||
| else: | |||||
| log_ = logger.log | |||||
| batch_time = AverageMeter() | |||||
| data_time = AverageMeter() | |||||
| losses = dict() | |||||
| losses['cls'] = AverageMeter() | |||||
| losses['sim'] = AverageMeter() | |||||
| check = time.time() | |||||
| for n, (images, labels) in enumerate(loader): | |||||
| model.train() | |||||
| count = n * P.n_gpus # number of trained samples | |||||
| data_time.update(time.time() - check) | |||||
| check = time.time() | |||||
| ### SimCLR loss ### | |||||
| if P.dataset != 'imagenet' and P.dataset != 'CNMC' and P.dataset != 'CNMC_grayscale': | |||||
| batch_size = images.size(0) | |||||
| images = images.to(device) | |||||
| images1, images2 = hflip(images.repeat(2, 1, 1, 1)).chunk(2) # hflip | |||||
| else: | |||||
| batch_size = images[0].size(0) | |||||
| images1, images2 = images[0].to(device), images[1].to(device) | |||||
| #print("\nImages" + str(images.shape) + "\n") | |||||
| images1 = torch.cat([torch.rot90(images1, rot, (2, 3)) for rot in range(4)]) # 4B | |||||
| images2 = torch.cat([torch.rot90(images2, rot, (2, 3)) for rot in range(4)]) # 4B | |||||
| images_pair = torch.cat([images1, images2], dim=0) # 8B | |||||
| labels = labels.to(device) | |||||
| rot_sim_labels = torch.cat([labels + P.n_classes * i for i in range(4)], dim=0) | |||||
| rot_sim_labels = rot_sim_labels.to(device) | |||||
| images_pair = simclr_aug(images_pair) # simclr augment | |||||
| _, outputs_aux = model(images_pair, simclr=True, penultimate=True) | |||||
| simclr = normalize(outputs_aux['simclr']) # normalize | |||||
| sim_matrix = get_similarity_matrix(simclr, multi_gpu=P.multi_gpu) | |||||
| loss_sim = Supervised_NT_xent(sim_matrix, labels=rot_sim_labels, | |||||
| temperature=0.07, multi_gpu=P.multi_gpu) * P.sim_lambda | |||||
| ### total loss ### | |||||
| loss = loss_sim | |||||
| optimizer.zero_grad() | |||||
| loss.backward() | |||||
| optimizer.step() | |||||
| scheduler.step(epoch - 1 + n / len(loader)) | |||||
| lr = optimizer.param_groups[0]['lr'] | |||||
| batch_time.update(time.time() - check) | |||||
| ### Post-processing stuffs ### | |||||
| penul_1 = outputs_aux['penultimate'][:batch_size] | |||||
| penul_2 = outputs_aux['penultimate'][4 * batch_size: 5 * batch_size] | |||||
| outputs_aux['penultimate'] = torch.cat([penul_1, penul_2]) # only use original rotation | |||||
| ### Linear evaluation ### | |||||
| outputs_linear_eval = linear(outputs_aux['penultimate'].detach()) | |||||
| loss_linear = criterion(outputs_linear_eval, labels.repeat(2)) | |||||
| linear_optim.zero_grad() | |||||
| loss_linear.backward() | |||||
| linear_optim.step() | |||||
| ### Log losses ### | |||||
| losses['cls'].update(0, batch_size) | |||||
| losses['sim'].update(loss_sim.item(), batch_size) | |||||
| if count % 50 == 0: | |||||
| log_('[Epoch %3d; %3d] [Time %.3f] [Data %.3f] [LR %.5f]\n' | |||||
| '[LossC %f] [LossSim %f]' % | |||||
| (epoch, count, batch_time.value, data_time.value, lr, | |||||
| losses['cls'].value, losses['sim'].value)) | |||||
| check = time.time() | |||||
| log_('[DONE] [Time %.3f] [Data %.3f] [LossC %f] [LossSim %f]' % | |||||
| (batch_time.average, data_time.average, | |||||
| losses['cls'].average, losses['sim'].average)) | |||||
| if logger is not None: | |||||
| logger.scalar_summary('train/loss_cls', losses['cls'].average, epoch) | |||||
| logger.scalar_summary('train/loss_sim', losses['sim'].average, epoch) | |||||
| logger.scalar_summary('train/batch_time', batch_time.average, epoch) | |||||
+ 39
- 0
training/unsup/__init__.py
View File
| def setup(mode, P): | |||||
| fname = f'{P.dataset}_{P.model}_unsup_{mode}_{P.res}' | |||||
| if mode == 'simclr': | |||||
| from .simclr import train | |||||
| elif mode == 'simclr_CSI': | |||||
| from .simclr_CSI import train | |||||
| fname += f'_shift_{P.shift_trans_type}_resize_factor{P.resize_factor}_color_dist{P.color_distort}' | |||||
| if P.shift_trans_type == 'gauss': | |||||
| fname += f'_gauss_sigma{P.gauss_sigma}' | |||||
| elif P.shift_trans_type == 'randpers': | |||||
| fname += f'_distortion_scale{P.distortion_scale}' | |||||
| elif P.shift_trans_type == 'sharp': | |||||
| fname += f'_sharpness_factor{P.sharpness_factor}' | |||||
| elif P.shift_trans_type == 'sharp': | |||||
| fname += f'_nmean_{P.noise_mean}_nstd_{P.noise_std}' | |||||
| else: | |||||
| raise NotImplementedError() | |||||
| if P.one_class_idx is not None: | |||||
| fname += f'_one_class_{P.one_class_idx}' | |||||
| if P.suffix is not None: | |||||
| fname += f'_{P.suffix}' | |||||
| return train, fname | |||||
| def update_comp_loss(loss_dict, loss_in, loss_out, loss_diff, batch_size): | |||||
| loss_dict['pos'].update(loss_in, batch_size) | |||||
| loss_dict['neg'].update(loss_out, batch_size) | |||||
| loss_dict['diff'].update(loss_diff, batch_size) | |||||
| def summary_comp_loss(logger, tag, loss_dict, epoch): | |||||
| logger.scalar_summary(f'{tag}/pos', loss_dict['pos'].average, epoch) | |||||
| logger.scalar_summary(f'{tag}/neg', loss_dict['neg'].average, epoch) | |||||
| logger.scalar_summary(f'{tag}', loss_dict['diff'].average, epoch) | |||||
BIN
training/unsup/__pycache__/__init__.cpython-36.pyc
View File
BIN
training/unsup/__pycache__/__init__.cpython-37.pyc
View File
BIN
training/unsup/__pycache__/simclr_CSI.cpython-36.pyc
View File
BIN
training/unsup/__pycache__/simclr_CSI.cpython-37.pyc
View File
+ 0
- 0
training/unsup/__pycache__/simclr_CSI.cpython-37.pyc.2078473038560
View File
+ 101
- 0
training/unsup/simclr.py
View File
| import time | |||||
| import torch.optim | |||||
| import models.transform_layers as TL | |||||
| from training.contrastive_loss import get_similarity_matrix, NT_xent | |||||
| from utils.utils import AverageMeter, normalize | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| hflip = TL.HorizontalFlipLayer().to(device) | |||||
| def train(P, epoch, model, criterion, optimizer, scheduler, loader, logger=None, | |||||
| simclr_aug=None, linear=None, linear_optim=None): | |||||
| assert simclr_aug is not None | |||||
| assert P.sim_lambda == 1.0 | |||||
| if logger is None: | |||||
| log_ = print | |||||
| else: | |||||
| log_ = logger.log | |||||
| batch_time = AverageMeter() | |||||
| data_time = AverageMeter() | |||||
| losses = dict() | |||||
| losses['cls'] = AverageMeter() | |||||
| losses['sim'] = AverageMeter() | |||||
| check = time.time() | |||||
| for n, (images, labels) in enumerate(loader): | |||||
| model.train() | |||||
| count = n * P.n_gpus # number of trained samples | |||||
| data_time.update(time.time() - check) | |||||
| check = time.time() | |||||
| ### SimCLR loss ### | |||||
| if P.dataset != 'imagenet': | |||||
| batch_size = images.size(0) | |||||
| images = images.to(device) | |||||
| images_pair = hflip(images.repeat(2, 1, 1, 1)) # 2B with hflip | |||||
| else: | |||||
| batch_size = images[0].size(0) | |||||
| images1, images2 = images[0].to(device), images[1].to(device) | |||||
| images_pair = torch.cat([images1, images2], dim=0) # 2B | |||||
| labels = labels.to(device) | |||||
| images_pair = simclr_aug(images_pair) # transform | |||||
| _, outputs_aux = model(images_pair, simclr=True, penultimate=True) | |||||
| simclr = normalize(outputs_aux['simclr']) # normalize | |||||
| sim_matrix = get_similarity_matrix(simclr, multi_gpu=P.multi_gpu) | |||||
| loss_sim = NT_xent(sim_matrix, temperature=0.5) * P.sim_lambda | |||||
| ### total loss ### | |||||
| loss = loss_sim | |||||
| optimizer.zero_grad() | |||||
| loss.backward() | |||||
| optimizer.step() | |||||
| scheduler.step(epoch - 1 + n / len(loader)) | |||||
| lr = optimizer.param_groups[0]['lr'] | |||||
| batch_time.update(time.time() - check) | |||||
| ### Post-processing stuffs ### | |||||
| simclr_norm = outputs_aux['simclr'].norm(dim=1).mean() | |||||
| ### Linear evaluation ### | |||||
| outputs_linear_eval = linear(outputs_aux['penultimate'].detach()) | |||||
| loss_linear = criterion(outputs_linear_eval, labels.repeat(2)) | |||||
| linear_optim.zero_grad() | |||||
| loss_linear.backward() | |||||
| linear_optim.step() | |||||
| ### Log losses ### | |||||
| losses['cls'].update(0, batch_size) | |||||
| losses['sim'].update(loss_sim.item(), batch_size) | |||||
| if count % 50 == 0: | |||||
| log_('[Epoch %3d; %3d] [Time %.3f] [Data %.3f] [LR %.5f]\n' | |||||
| '[LossC %f] [LossSim %f]' % | |||||
| (epoch, count, batch_time.value, data_time.value, lr, | |||||
| losses['cls'].value, losses['sim'].value)) | |||||
| check = time.time() | |||||
| log_('[DONE] [Time %.3f] [Data %.3f] [LossC %f] [LossSim %f]' % | |||||
| (batch_time.average, data_time.average, | |||||
| losses['cls'].average, losses['sim'].average)) | |||||
| if logger is not None: | |||||
| logger.scalar_summary('train/loss_cls', losses['cls'].average, epoch) | |||||
| logger.scalar_summary('train/loss_sim', losses['sim'].average, epoch) | |||||
| logger.scalar_summary('train/batch_time', batch_time.average, epoch) |
+ 114
- 0
training/unsup/simclr_CSI.py
View File
| import time | |||||
| import torch.optim | |||||
| import models.transform_layers as TL | |||||
| from training.contrastive_loss import get_similarity_matrix, NT_xent | |||||
| from utils.utils import AverageMeter, normalize | |||||
| device = torch.device(f"cuda" if torch.cuda.is_available() else "cpu") | |||||
| hflip = TL.HorizontalFlipLayer().to(device) | |||||
| def train(P, epoch, model, criterion, optimizer, scheduler, loader, logger=None, | |||||
| simclr_aug=None, linear=None, linear_optim=None): | |||||
| assert simclr_aug is not None | |||||
| assert P.sim_lambda == 1.0 # to avoid mistake | |||||
| assert P.K_shift > 1 | |||||
| if logger is None: | |||||
| log_ = print | |||||
| else: | |||||
| log_ = logger.log | |||||
| batch_time = AverageMeter() | |||||
| data_time = AverageMeter() | |||||
| losses = dict() | |||||
| losses['cls'] = AverageMeter() | |||||
| losses['sim'] = AverageMeter() | |||||
| losses['shift'] = AverageMeter() | |||||
| check = time.time() | |||||
| for n, (images, labels) in enumerate(loader): | |||||
| model.train() | |||||
| count = n * P.n_gpus # number of trained samples | |||||
| data_time.update(time.time() - check) | |||||
| check = time.time() | |||||
| ### SimCLR loss ### | |||||
| if P.dataset != 'imagenet' and P.dataset != 'CNMC' and P.dataset != 'CNMC_grayscale': | |||||
| batch_size = images.size(0) | |||||
| images = images.to(device) | |||||
| images1, images2 = hflip(images.repeat(2, 1, 1, 1)).chunk(2) # hflip | |||||
| else: | |||||
| batch_size = images[0].size(0) | |||||
| images1, images2 = images[0].to(device), images[1].to(device) | |||||
| labels = labels.to(device) | |||||
| images1 = torch.cat([P.shift_trans(images1, k) for k in range(P.K_shift)]) | |||||
| images2 = torch.cat([P.shift_trans(images2, k) for k in range(P.K_shift)]) | |||||
| shift_labels = torch.cat([torch.ones_like(labels) * k for k in range(P.K_shift)], 0) # B -> 4B | |||||
| shift_labels = shift_labels.repeat(2) | |||||
| images_pair = torch.cat([images1, images2], dim=0) # 8B | |||||
| images_pair = simclr_aug(images_pair) # transform | |||||
| _, outputs_aux = model(images_pair, simclr=True, penultimate=True, shift=True) | |||||
| simclr = normalize(outputs_aux['simclr']) # normalize | |||||
| sim_matrix = get_similarity_matrix(simclr, multi_gpu=P.multi_gpu) | |||||
| loss_sim = NT_xent(sim_matrix, temperature=0.5) * P.sim_lambda | |||||
| loss_shift = criterion(outputs_aux['shift'], shift_labels) | |||||
| ### total loss ### | |||||
| loss = loss_sim + loss_shift | |||||
| optimizer.zero_grad() | |||||
| loss.backward() | |||||
| optimizer.step() | |||||
| scheduler.step(epoch - 1 + n / len(loader)) | |||||
| lr = optimizer.param_groups[0]['lr'] | |||||
| batch_time.update(time.time() - check) | |||||
| ### Post-processing stuffs ### | |||||
| simclr_norm = outputs_aux['simclr'].norm(dim=1).mean() | |||||
| penul_1 = outputs_aux['penultimate'][:batch_size] | |||||
| penul_2 = outputs_aux['penultimate'][P.K_shift * batch_size: (P.K_shift + 1) * batch_size] | |||||
| outputs_aux['penultimate'] = torch.cat([penul_1, penul_2]) # only use original rotation | |||||
| ### Linear evaluation ### | |||||
| outputs_linear_eval = linear(outputs_aux['penultimate'].detach()) | |||||
| loss_linear = criterion(outputs_linear_eval, labels.repeat(2)) | |||||
| linear_optim.zero_grad() | |||||
| loss_linear.backward() | |||||
| linear_optim.step() | |||||
| losses['cls'].update(0, batch_size) | |||||
| losses['sim'].update(loss_sim.item(), batch_size) | |||||
| losses['shift'].update(loss_shift.item(), batch_size) | |||||
| if count % 50 == 0: | |||||
| log_('[Epoch %3d; %3d] [Time %.3f] [Data %.3f] [LR %.5f]\n' | |||||
| '[LossC %f] [LossSim %f] [LossShift %f]' % | |||||
| (epoch, count, batch_time.value, data_time.value, lr, | |||||
| losses['cls'].value, losses['sim'].value, losses['shift'].value)) | |||||
| log_('[DONE] [Time %.3f] [Data %.3f] [LossC %f] [LossSim %f] [LossShift %f]' % | |||||
| (batch_time.average, data_time.average, | |||||
| losses['cls'].average, losses['sim'].average, losses['shift'].average)) | |||||
| if logger is not None: | |||||
| logger.scalar_summary('train/loss_cls', losses['cls'].average, epoch) | |||||
| logger.scalar_summary('train/loss_sim', losses['sim'].average, epoch) | |||||
| logger.scalar_summary('train/loss_shift', losses['shift'].average, epoch) | |||||
| logger.scalar_summary('train/batch_time', batch_time.average, epoch) | |||||
+ 0
- 0
utils/__init__.py
View File
Some files were not shown because too many files changed in this diff
Loading…